クマ、ETS、ビーツ

私たちが何度も行ってきたことの一つは、プロセスとして何らかのストレージデバイスを実装することです。物を保存するために冷蔵庫を作り、プロセスを登録するためのregisを作り、キー/バリューストアなどを見てきました。もし私たちがオブジェクト指向設計を行うプログラマーであれば、シングルトンが大量に浮遊し、特別なストレージクラスなどが存在するでしょう。実際、dictやgb_treesのようなデータ構造をプロセスでラップすることは、それに少し似ています。
プロセス内にデータ構造を保持することは、実際には多くの場合に適しています。たとえば、プロセス内の内部状態として、タスクを実行するために実際にそのデータが必要な場合などです。私たちは多くの有効な使い方をしてきましたし、それを変更するべきではありません。しかし、最も最適な選択肢ではない可能性のあるケースが1つあります。それは、プロセスが他のプロセスと共有するためだけにデータ構造を保持している場合です。
私たちが書いたアプリケーションの1つがそれに該当します。どれか推測できますか?もちろんできます。前回の章の終わりに述べました。regisを書き換える必要があります。それは、それが機能しないとか、自分の仕事をうまくできないということではなく、潜在的に多数の他のプロセスとデータを共有するためのゲートウェイとして機能しているため、アーキテクチャ上の問題があるからです。
regisは、Process Quest(およびそれを使用する他のすべて)でメッセージングを行うための中央アプリケーションであり、名前付きプロセスに送信されるほぼすべてのメッセージは、それを通過する必要があります。これは、独立したアクターでアプリケーションを非常に並行化し、スケールアップに適した監視構造を確保したにもかかわらず、すべての操作が、メッセージに一つずつ応答する必要がある中央のregisプロセスに依存することを意味します。
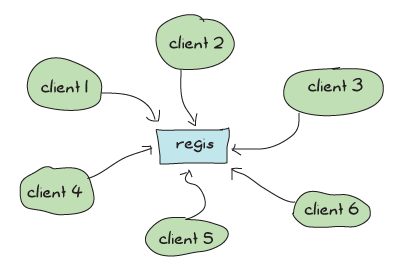
大量のメッセージパッシングが行われると、regisはますます忙しくなるリスクがあり、需要が高くなると、システム全体がシーケンシャルになり、遅くなります。それはかなり悪いことです。
注:Process Quest内でregisがボトルネックであるという直接的な証拠はありません。実際、Process Questは、他の多くのアプリケーションと比較して、メッセージングが非常に少ないです。regisを、より多くのメッセージングとルックアップを必要とする何かに使用していた場合、問題はより明白になるでしょう。
それを回避するいくつかの方法は、regisをサブプロセスに分割してデータをシャーディングすることでルックアップを高速化するか、並列および同時アクセスが可能なデータベースにデータを保存する方法を見つけることです。最初の方法を検討するのは非常に興味深いですが、後者の簡単な方法を試してみましょう。
Erlangには、ETS(Erlang Term Storage)テーブルと呼ばれるものがあります。ETSテーブルは、Erlang仮想マシンに含まれる効率的なインメモリデータベースです。破壊的な更新が許可されており、ガベージコレクションが近づかない仮想マシンの部分にあります。それらは一般的に高速であり、Erlangプログラマーがコードの一部が遅くなりすぎた場合に最適化するための非常に簡単な方法です。
ETSテーブルは、読み取りおよび書き込みにおける限定的な並行性を(プロセスのメールボックスにまったく並行性がないよりもはるかに優れています)提供します。これにより、多くの痛みを最適化して取り除くことができます。
Kool-Aidを飲みすぎないでください
ETSテーブルは最適化するための優れた方法ですが、それでも慎重に使用する必要があります。デフォルトでは、VMは1400個のETSテーブルに制限されています。その数を変更すること(erl -env ERL_MAX_ETS_TABLES Number)は可能ですが、このデフォルトの低いレベルは、一般にプロセスごとに1つのテーブルを持つことを避ける必要があることを示す良い兆候です。
しかし、regisをETSを使用するように書き換える前に、ETSの原則を少し理解する必要があります。
ETSの概念
ETSテーブルは、etsモジュール内のBIFとして実装されています。ETSの主な設計目標は、Erlangに大量のデータを一定のアクセス時間で保存する方法を提供すること(関数型データ構造は通常、対数アクセス時間で推移する傾向があります)、およびそのようなストレージが、その使用法を単純かつ慣用的であるようにプロセスとして実装されているかのように見せることでした。
注:テーブルがプロセスのように見えるということは、テーブルをスポーンしたり、リンクしたりできるという意味ではなく、何も共有しないというセマンティクスを尊重し、関数型インターフェースの背後に呼び出しをラップし、Erlangの任意のネイティブデータ型を処理し、名前を付けることができる(別のレジストリで)、などの意味です。
すべてのETSテーブルは、ネイティブに任意のものを格納するErlangタプルを格納します。このタプル要素の1つが、ソートに使用するプライマリキーとして機能します。つまり、{Name, Age, PhoneNumber, Email}の形式の人のタプルを使用すると、次のようなテーブルを持つことができます
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
...
したがって、テーブルのインデックスをメールアドレスにしたい場合は、ETSにキーの位置を4に設定するように指示することでこれを行うことができます(実際のETS関数呼び出しに入ったときに、これを行う方法を少し詳しく見ていきます)。キーを決定したら、テーブルにデータを格納するさまざまな方法を選択できます
- set
- セットテーブルでは、各キーインスタンスが一意である必要があることを示します。上記のデータベースに重複したメールがあってはなりません。セットは、定数時間アクセスで標準のキー/バリューストアを使用する必要がある場合に最適です。
- ordered_set
- テーブルごとにキーインスタンスは1つしか存在できませんが、
ordered_setは他のいくつかの興味深いプロパティを追加します。1つ目は、ordered_setテーブルの要素が順序付けされることです(誰がそう思うでしょうか?!)。テーブルの最初の要素は最も小さい要素であり、最後の要素は最も大きい要素です。テーブルを繰り返し(次の要素に何度もジャンプして)トラバースすると、値は増加するはずです。これは、setテーブルでは必ずしも当てはまりません。順序付きセットテーブルは、範囲を頻繁に操作する必要がある場合に最適です(エントリ12〜50が必要!)。ただし、アクセス時間が遅くなるという欠点があります(Nは保存されたオブジェクトの数で、O(log N)になります)。 - bag
- バッグテーブルには、タプル自体が異なる限り、同じキーを持つ複数のエントリを含めることができます。これは、テーブルに
{key, some, values}と{key, other, values}を問題なく含めることができることを意味します。これは、セットでは不可能です(同じキーを持つため)。ただし、まったく同一であるため、テーブルに{key, some, values}を2回含めることはできません。 - duplicate_bag
- このタイプのテーブルは、
bagテーブルのように機能しますが、完全に同一のタプルを同じテーブル内に複数回保持できるという点が異なります。
注: ordered_setテーブルでは、すべての操作で値1と1.0が同一と見なされます。他のテーブルでは、それらは異なるものと見なされます。
最後に学習する必要がある一般的な概念は、ETSテーブルには、ソケットと同様に、制御プロセスの概念があることです。プロセスが新しいETSテーブルを開始する関数を呼び出すと、そのプロセスがテーブルの所有者になります。
デフォルトでは、テーブルの所有者のみがテーブルに書き込むことができますが、誰もがそこから読み取ることができます。これは、保護されたレベルのアクセス許可として知られています。また、アクセス許可をパブリック(誰もが読み書きできる)、またはプライベート(所有者のみが読み書きできる)に設定することもできます。

テーブルの所有権の概念はもう少し進んでいます。ETSテーブルはプロセスと密接にリンクしています。プロセスが終了すると、テーブルが消えます(そして、そのすべてのコンテンツも消えます)。ただし、ソケットとその制御プロセスで行ったように、テーブルを譲渡したり、所有者プロセスが終了した場合にテーブルが自動的に後継プロセスに譲渡されるように、後継者を決定したりすることができます。
ETSから家に電話をかける
ETSテーブルを開始するには、関数ets:new/2を呼び出す必要があります。関数は、引数Nameとオプションのリストを受け取ります。戻り値として、テーブルを使用するために必要な一意の識別子を取得します。これは、プロセスのPidに相当します。オプションは次のいずれかになります
Type = set | ordered_set | bag | duplicate_bag- 前のセクションで説明したように、テーブルのタイプを設定します。デフォルト値は
setです。 Access = private | protected | public- 前に説明したように、テーブルのアクセス許可を設定できます。デフォルトのオプションは
protectedです。 named_table- 面白いことに、
ets:new(some_name, [])を呼び出すと、名前のない保護されたセットテーブルが開始されます。名前がテーブルに接続するための方法として使用されるように(そして一意になるように)、オプションnamed_tableを関数に渡す必要があります。そうしないと、テーブルの名前は純粋にドキュメント用となり、システム内のすべてのETSテーブルに関する情報を出力するets:i()などの関数に表示されます。 {keypos, Position}- ご存じ(または覚えておくべき)ように、ETSテーブルはタプルを格納することで機能します。Positionパラメータは、データベーステーブルのプライマリキーとして機能する各タプルの要素を指定する1からNまでの整数を保持します。デフォルトのキー位置は1に設定されています。これは、レコードを使用する場合、各レコードの最初の要素が常にレコードの名前になるため(タプル形式での外観を思い出してください)、注意する必要があることを意味します。任意のフィールドをキーとして使用する場合は、
{keypos, #RecordName.FieldName}を使用します。これは、レコードのタプル表現内のFieldNameの位置を返します。 {heir, Pid, Data} | {heir, none}- 前のセクションで述べたように、ETSテーブルには親として機能するプロセスがあります。そのプロセスが終了すると、テーブルは消えます。テーブルにアタッチされたデータが保持したいものであれば、継承者を定義することが役立ちます。テーブルにアタッチされたプロセスが終了した場合、継承者は
{'ETS-TRANSFER', TableId, FromPid, Data}というメッセージを受け取ります。ここで、Data はオプションが最初に定義されたときに渡された要素です。テーブルは自動的に継承者に継承されます。デフォルトでは、継承者は定義されていません。後でets:setopts(Table, {heir, Pid, Data})またはets:setopts(Table, {heir, none})を呼び出すことで、継承者を定義または変更することができます。テーブルを単に譲渡したい場合は、ets:give_away/3を呼び出します。 {read_concurrency, true | false}- これは、テーブルを読み込み並行処理用に最適化するためのオプションです。このオプションを true に設定すると、読み込みのコストが大幅に削減されますが、書き込みへの切り替えのコストが大幅に増加します。基本的に、このオプションは、読み込みが多く、書き込みが少ない場合に、パフォーマンスを向上させるために有効にする必要があります。読み込みと書き込みがいくつかインターリーブしている場合は、このオプションを使用すると、パフォーマンスが低下する可能性があります。
{write_concurrency, true | false}- 通常、テーブルへの書き込みはテーブル全体をロックし、書き込みが完了するまで、他のユーザーは読み書きの両方でアクセスできません。このオプションを 'true' に設定すると、ETSのACIDプロパティに影響を与えることなく、読み書きの両方を同時に実行できます。ただし、これを行うと、単一のプロセスによるシーケンシャル書き込みのパフォーマンスと、同時読み込みの容量が低下します。書き込みと読み込みの両方が大量に発生する場合は、このオプションを 'read_concurrency' と組み合わせて使用できます。
compressed- このオプションを使用すると、テーブル内のデータは、主キー以外のほとんどのフィールドで圧縮されます。これにより、次の関数で見るように、テーブルの要素全体を検査する際のパフォーマンスが低下します。
次に、テーブル作成の反対はテーブルの破棄です。そのためには、ets:delete(Table) を呼び出すだけで済みます。ここで、Table はテーブルIDまたは名前付きテーブルの名前です。テーブルから単一のエントリを削除したい場合は、非常に似た関数呼び出しが必要です。ets:delete(Table, Key)。
非常に基本的なテーブル処理には、さらに2つの関数が必要です。insert(Table, ObjectOrObjects) および lookup(Table, Key)。 insert/2 の場合、ObjectOrObjects は、挿入する単一のタプルまたはタプルのリストのいずれかです。
1> ets:new(ingredients, [set, named_table]).
ingredients
2> ets:insert(ingredients, {bacon, great}).
true
3> ets:lookup(ingredients, bacon).
[{bacon,great}]
4> ets:insert(ingredients, [{bacon, awesome}, {cabbage, alright}]).
true
5> ets:lookup(ingredients, bacon).
[{bacon,awesome}]
6> ets:lookup(ingredients, cabbage).
[{cabbage,alright}]
7> ets:delete(ingredients, cabbage).
true
8> ets:lookup(ingredients, cabbage).
[]
lookup 関数がリストを返すことに気付くでしょう。セットベースのテーブルは常に最大1つの項目しか返さない場合でも、すべてのタイプのテーブルでそうします。これは、バッグまたは重複バッグ(単一のキーに対して多くの値を返す可能性があります)を使用する場合でも、lookup 関数を汎用的に使用できる必要があることを意味します。
上記のスニペットで発生するもう1つのことは、同じキーを2回挿入すると上書きされることです。これは常にセットおよび順序付きセットで発生しますが、バッグまたは重複バッグでは発生しません。これを回避したい場合は、関数 ets:insert_new/2 が役立つかもしれません。これは、要素がテーブルにまだ存在しない場合にのみ要素を挿入します。
注: ETSテーブルでは、タプルはすべて同じサイズである必要はありませんが、そうすることが良い習慣と見なされるべきです。ただし、タプルはキーの位置のサイズ以上(またはそれ以上)である必要があります。
タプルの一部のみをフェッチする必要がある場合は、別の検索関数があります。その関数は lookup_element(TableID, Key, PositionToReturn) であり、一致した要素(または、バッグまたは重複バッグテーブルで複数ある場合はそれらのリスト)を返します。要素がない場合、関数は理由として badarg でエラーになります。
いずれにしても、バッグで再度試してみましょう
9> TabId = ets:new(ingredients, [bag]).
16401
10> ets:insert(TabId, {bacon, delicious}).
true
11> ets:insert(TabId, {bacon, fat}).
true
12> ets:insert(TabId, {bacon, fat}).
true
13> ets:lookup(TabId, bacon).
[{bacon,delicious},{bacon,fat}]
これはバッグであるため、{bacon, fat} は2回挿入しましたが、1回しか存在しません。ただし、複数の 'bacon' エントリを持つことができることがわかります。ここで注目すべきもう1つの点は、named_table オプションを渡さずに、テーブルを使用するには TableId を使用する必要があることです。
注: これらの例をコピーしている間にシェルがクラッシュした場合、テーブルは親プロセス(シェル)が消えたため、消えてしまいます。
最後に使用できる基本的な操作は、テーブルを1つずつトラバースすることです。注意していれば、ordered_set テーブルがこれに最適であることがわかります
14> ets:new(ingredients, [ordered_set, named_table]).
ingredients
15> ets:insert(ingredients, [{ketchup, "not much"}, {mustard, "a lot"}, {cheese, "yes", "goat"}, {patty, "moose"}, {onions, "a lot", "caramelized"}]).
true
16> Res1 = ets:first(ingredients).
cheese
17> Res2 = ets:next(ingredients, Res1).
ketchup
18> Res3 = ets:next(ingredients, Res2).
mustard
19> ets:last(ingredients).
patty
20> ets:prev(ingredients, ets:last(ingredients)).
onions
ご覧のとおり、要素はソート順になり、順方向と逆方向の両方で1つずつアクセスできます。ああ、それから境界条件で何が起こるかを確認する必要があります
21> ets:next(ingredients, ets:last(ingredients)). '$end_of_table' 22> ets:prev(ingredients, ets:first(ingredients)). '$end_of_table'
$ で始まるアトムが表示された場合は、それらが何かについて教えてくれるOTPチームによる(慣例的に選択された)特別な値であることを知っておく必要があります。テーブルの外側を反復処理しようとすると、これらの $end_of_table アトムが表示されます。
したがって、ETSを非常に基本的なキー値ストアとして使用する方法はわかりました。キーのマッチング以上のものが必要な場合は、より高度な使用法があります。
一致の確認

より特殊なメカニズムからレコードを見つける場合に使用できるETSの関数はたくさんあります。
考えてみると、最適な選択方法はパターンマッチングです。理想的なシナリオは、マッチングするパターンを(変数またはデータ構造として)保存し、それを何らかのETS関数に渡し、その関数に処理を任せることができることです。
これは高階パターンマッチングと呼ばれ、残念ながらErlangでは使用できません。実際、それを持っている言語はほとんどありません。代わりに、Erlangには、Erlangプログラマーが合意したサブ言語があり、それがパターンマッチングを通常のデータ構造の束として記述するために使用されています。
この表記法は、ETSとうまく適合するようにタプルに基づいています。これにより、パターンマッチングを行うためにタプルと混在させることができる変数(通常の変数と「気にしない」変数)を指定できます。変数は、'$0'、'$1'、'$2' のように記述されます(数値は、結果を取得する方法を除いて重要ではありません)。「気にしない」変数は、'_' として記述できます。これらのアトムはすべて、次のようなタプルで形式をとることができます
{items, '$3', '$1', '_', '$3'}
これは、通常のパターンマッチングで {items, C, A, _, C} と言うのとほぼ同じです。したがって、最初の要素はアトム items である必要があり、タプルの2番目と5番目のスロットは同一である必要があるなどと推測できます。
より実用的な設定でこの表記法を使用するには、2つの関数 match/2 と match_object/2 が利用可能です(match/3 と match_object/3 も利用可能ですが、この章の範囲外であり、詳細はドキュメントを確認することをお勧めします)。前者はパターンの変数を返し、後者はパターンに一致したエントリ全体を返します。
1> ets:new(table, [named_table, bag]).
table
2> ets:insert(table, [{items, a, b, c, d}, {items, a, b, c, a}, {cat, brown, soft, loveable, selfish}, {friends, [jenn,jeff,etc]}, {items, 1, 2, 3, 1}]).
true
3> ets:match(table, {items, '$1', '$2', '_', '$1'}).
[[a,b],[1,2]]
4> ets:match(table, {items, '$114', '$212', '_', '$6'}).
[[d,a,b],[a,a,b],[1,1,2]]
5> ets:match_object(table, {items, '$1', '$2', '_', '$1'}).
[{items,a,b,c,a},{items,1,2,3,1}]
6> ets:delete(table).
true
関数としての match/2-3 の優れた点は、返されるために厳密に必要なものだけを返すことです。これは、前述のように、ETSテーブルが共有なしの理想に従っているため便利です。非常に大きなレコードがある場合は、必要なフィールドのみをコピーするのが適切かもしれません。いずれにせよ、変数の数値に明確な意味はないものの、その順序が重要であることにも気付くでしょう。返された値の最終リストでは、パターンによって $114 にバインドされた値は常に $6 にバインドされた値の後に来ます。何も一致しない場合は、空のリストが返されます。
このようなパターンマッチに基づいてエントリを削除したい場合もあるかもしれません。このような場合、ets:match_delete(Table, Pattern) 関数が役立ちます。

これはすべて問題なく、奇妙な方法で基本的なパターンマッチングを行うために任意の種類の値を設定できます。比較や範囲、出力の書式設定(リストが目的のものではない可能性がある)などを行うことができれば、非常に便利です。ああ、待って、できます!
選ばれました
これは、非常に単純なガードを含め、真の関数ヘッダーレベルのパターンマッチングと同等のものを取得する場所です。以前にSQLデータベースを使用したことがある場合は、他の要素よりも大きい、等しい、小さいなどの要素を比較するクエリを実行する方法を見たことがあるかもしれません。これがここで求めている種類のものです。
したがって、Erlangの背後にいる人々は、マッチングで見た構文を採用し、十分に強力になるまで、クレイジーな方法でそれを拡張しました。残念ながら、読みにくくもなりました。それは次のようになります
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
これはかなり醜く、子供に見せたくないデータ構造です。信じられないかもしれませんが、マッチ仕様と呼ばれるこれらのものを書く方法を学びます。その形式では、理由もなく少し難しすぎます。それでも、読み方は学びます!より高いレベルのビューからの見え方は次のとおりです
[{InitialPattern1, Guards1, ReturnedValue1},
{InitialPattern2, Guards2, ReturnedValue2}].
または、さらに高いビューから
[Clause1, Clause2]
そうです、そのようなものは、大まかに言うと、関数ヘッダーのパターン、次にガード、次に関数の本体を表します。形式は、マッチ関数の場合と同じように、最初のパターンには '$N' 変数に制限されています。新しいセクションはガードパターンであり、通常のガードと非常によく似たことを実行できます。ガード [{'<','$3',4.0},{is_float,'$3'}] をよく見ると、ガードとして ... when Var < 4.0, is_float(Var) -> ... と非常によく似ていることがわかります。
次のガードは、今回はより複雑です。
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}]
それを翻訳すると、... when Var4 > 150 andalso Var4 < 500, Var2 == meat orelse Var2 == dairy -> ... のようなガードになります。わかりましたか?
各演算子またはガード関数は、プレフィックス構文で動作します。つまり、{関数または演算子, 引数1, ..., 引数N} の順序で使用します。したがって、is_list(X) は {is_list, '$1'} になり、X andalso Y は {'andalso', X, Y} になるなどです。andalso、orelse のような予約語や == のような演算子は、Erlangパーサーがエラーにならないようにアトムに入れる必要があります。
パターンの最後のセクションは、返したいものです。必要な変数をそこに入れるだけです。マッチ仕様の完全な入力を返したい場合は、変数 '$_' を使用します。 マッチ仕様の完全な仕様 は、Erlangドキュメントにあります。
前述したように、そのような方法でパターンを記述する方法は学習しません。もっと良い方法があります。ETSには、パース変換と呼ばれるものが付属しています。パース変換は、コンパイルフェーズの途中でErlangのパースツリーにアクセスするための、文書化されていない(したがってOTPチームによってサポートされていない)方法です。これによって、大胆なErlangプログラマーは、モジュール内のコードを新しい別の形式に変換できます。パース変換は、言語の構文やトークンを変更しない限り、ほとんど何でもでき、既存のErlangコードをほぼ何でも変更できます。
ETSに付属しているパース変換は、必要なモジュールごとに手動で有効にする必要があります。モジュールでそれを行う方法は次のとおりです
-module(SomeModule).
-include_lib("stdlib/include/ms_transform.hrl").
...
some_function() ->
ets:fun2ms(fun(X) when X > 4 -> X end).
-include_lib("stdlib/include/ms_transform.hrl"). という行には、モジュール内で使用されるたびに ets:fun2ms(SomeLiteralFun) の意味を上書きする特別なコードが含まれています。高階関数であるというよりも、パース変換はfun(パターン、ガード、戻り値)の内容を分析し、ets:fun2ms/1 の関数呼び出しを削除し、それを実際のマッチ仕様に置き換えます。奇妙ですよね?最も良いのは、これがコンパイル時に発生するため、この方法を使用することにオーバーヘッドがないことです。
インクルードファイルなしで、シェルで試すことができます
1> ets:fun2ms(fun(X) -> X end).
[{'$1',[],['$1']}]
2> ets:fun2ms(fun({X,Y}) -> X+Y end).
[{{'$1','$2'},[],[{'+','$1','$2'}]}]
3> ets:fun2ms(fun({X,Y}) when X < Y -> X+Y end).
[{{'$1','$2'},[{'<','$1','$2'}],[{'+','$1','$2'}]}]
4> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0 -> X+Y end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
[{'+','$1','$2'}]}]
5> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0; Y == 0 -> X end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
['$1']},
{{'$1','$2'},[{'==','$2',0}],['$1']}]
これらすべて!今ではとても簡単に書けます!そしてもちろん、funははるかに読みやすくなっています。セクションの最初にある複雑な例はどうでしょうか?funとして書くと次のようになります
6> ets:fun2ms(fun({Food, Type, <<1>>, Price, Calories}) when Calories > 150 andalso Calories < 500, Type == meat orelse Type == dairy; Price < 4.00, is_float(Price) -> Food end).
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
一見すると正確には意味が通じませんが、少なくとも、変数が数字ではなく名前を持つことができる場合、それが何を意味するのかを理解するのははるかに簡単です。注意すべきことの1つは、すべてのfunが有効なマッチ仕様であるとは限らないことです
7> ets:fun2ms(fun(X) -> my_own_function(X) end).
Error: fun containing the local function call 'my_own_function/1' (called in body) cannot be translated into match_spec
{error,transform_error}
8> ets:fun2ms(fun(X,Y) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
9> ets:fun2ms(fun([X,Y]) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
10> ets:fun2ms(fun({<<X/binary>>}) -> ok end).
Error: fun head contains bit syntax matching of variable 'X', which cannot be translated into match_spec
{error,transform_error}
関数ヘッダーは単一の変数またはタプルと一致する必要があり、ガード以外の関数は戻り値の一部として呼び出すことはできず、バイナリ内からの値の割り当ては許可されていませんなど。シェルで色々試してみて、何ができるかを確認してください。
Kool-Aidを飲みすぎないでくださいets:fun2ms のような関数は、とても素晴らしいように聞こえますよね!注意が必要です。問題点は、シェル内では ets:fun2ms が動的なfunを処理できる場合(funを渡すと、それらをそのまま処理します)、これはコンパイル済みモジュールでは不可能だということです。
これは、Erlangには2種類のfunがあるためです。シェルfunとモジュールfunです。モジュールfunは、仮想マシンが理解できるコンパクトな形式にコンパイルされます。それらは不透明で、内部がどうなっているかを知るために検査することはできません。
一方、シェルfunはまだ評価されていない抽象的な用語です。それらはシェルがそれらに対して評価器を呼び出すことができるように作成されています。したがって、関数fun2ms には、コンパイルされたコードを取得する場合と、シェルにいる場合の2つのバージョンがあります。
これは問題ありませんが、funは異なる種類のfunと互換性がありません。つまり、コンパイルされたfunを取得してシェルで ets:fun2ms を呼び出したり、動的なfunを取得してそこで fun2ms を呼び出すコンパイルされたコードに送信したりすることはできません。残念!
マッチ仕様を役立つものにするには、それを使用するのが理にかなっています。これは、結果を取得するために関数ets:select/2 を使用し、ordered_set テーブルで結果を逆順に取得するために ets:select_reverse/2 を使用し(他の型では、select/2 と同じ)、仕様に一致する結果の数を知るために ets:select_count/2 を使用し、マッチ仕様に一致するレコードを削除するために ets:select_delete(Table, MatchSpec) を使用することで実行できます。
試してみましょう。まず、テーブルのレコードを定義し、さまざまな商品を入力します
11> rd(food, {name, calories, price, group}).
food
12> ets:new(food, [ordered_set, {keypos,#food.name}, named_table]).
food
13> ets:insert(food, [#food{name=salmon, calories=88, price=4.00, group=meat},
13> #food{name=cereals, calories=178, price=2.79, group=bread},
13> #food{name=milk, calories=150, price=3.23, group=dairy},
13> #food{name=cake, calories=650, price=7.21, group=delicious},
13> #food{name=bacon, calories=800, price=6.32, group=meat},
13> #food{name=sandwich, calories=550, price=5.78, group=whatever}]).
true
次に、特定のカロリー数以下の食品を選択してみることができます
14> ets:select(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = cereals,calories = 178,price = 2.79,group = bread},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = sandwich,calories = 550,price = 5.78,group = whatever}]
15> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = sandwich,calories = 550,price = 5.78,group = whatever},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
または、欲しいものがおいしい食べ物だけかもしれません
16> ets:select(food, ets:fun2ms(fun(N = #food{group=delicious}) -> N end)).
[#food{name = cake,calories = 650,price = 7.21,group = delicious}]
削除には少し特殊な工夫が必要です。あらゆる種類の値ではなく、パターンで true を返す必要があります
17> ets:select_delete(food, ets:fun2ms(fun(#food{price=P}) when P > 5 -> true end)).
3
18> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
そして最後の選択が示すように、5.00ドルを超えるアイテムはテーブルから削除されました。
テーブルをリストまたはファイルに変換する方法 (ets:tab2list/1、ets:tab2file/1、ets:file2tab/1) 、すべてのテーブルに関する情報を取得する方法 (ets:i/0, ets:info(Table)) など、ETS内にはさらに多くの関数があります。この場合、公式ドキュメントを参照することを強くお勧めします。
また、特定のErlang VM上のETSテーブルを視覚的に管理するために使用できるタブがある observer というアプリケーションもあります。wx サポートでErlangがビルドされている場合は、observer:start() を呼び出し、テーブルビューアータブを選択するだけです。古いErlangリリースでは、observer は存在せず、代わりに非推奨となった tv アプリケーション (tv:start()) を使用する必要がある場合があります。
DETS
DETSは、ディスクベースのETSバージョンであり、いくつかの重要な違いがあります。
ordered_set テーブルはもうなく、DETSファイルのディスクサイズ制限は2GBで、prev/1 や next/1 などの操作は、それほど安全でも高速でもありません。
テーブルの起動と停止が少し変更されました。新しいデータベーステーブルは、dets:open_file/2 を呼び出すことで作成され、dets:close/1 を実行することで閉じられます。テーブルは後で dets:open_file/1 を呼び出すことで再度開くことができます。
それ以外の場合、APIはほぼ同じであるため、ファイル内でのデータの書き込みと検索を処理する非常に簡単な方法を持つことが可能です。
Kool-Aidを飲みすぎないでください
DETSはディスクのみのデータベースであるため、遅くなる可能性があります。ETSとDETSテーブルを、RAMとディスクの両方に格納する、やや効率的なデータベースに結合したいと感じるかもしれません。
そうしたい場合は、シャーディング、トランザクション、および分散のサポートを追加しながら、まさに同じことを行うデータベースとしてMnesiaを検討することをお勧めします。
少し会話を減らして、少し行動に移しましょう

このやや長いセクションタイトル(および長い前のセクション)に続いて、最初に私たちをここに導いた実際的な問題に移ります。それは、レジスがETSを使用するように更新し、いくつかの潜在的なボトルネックを取り除くことです。
始める前に、操作をどのように処理し、安全なものと安全でないものを考える必要があります。安全であるべきものは、何も変更せず、1つのクエリに限定されているものです(時間の経過とともに3〜4回ではない)。それらは誰でもいつでも実行できます。テーブルへの書き込み、レコードの更新、削除、または複数のリクエストにわたって一貫性を必要とする方法での読み取りに関連するその他すべては、安全でないと見なされます。
ETSにはトランザクションがまったくないため、安全でない操作はすべて、テーブルを所有するプロセスによって実行される必要があります。安全な操作は、所有者プロセスの外部で実行される公開を許可する必要があります。レジスを更新する際に、このことを念頭に置いておきます。
最初のステップは、regis-1.0.0 のコピーを regis-1.1.0 として作成することです。ここでは、変更によって既存のインターフェースが壊れることはなく、技術的にはバグ修正ではないため、3番目の数字ではなく2番目の数字を増やすだけで、機能アップグレードと見なされます。
その新しいディレクトリでは、最初は regis_server.erl のみを操作する必要があります。インターフェースはそのまま維持するため、構造に関する残りの部分はあまり変更する必要がないはずです。
%%% The core of the app: the server in charge of tracking processes.
-module(regis_server).
-behaviour(gen_server).
-include_lib("stdlib/include/ms_transform.hrl").
-export([start_link/0, stop/0, register/2, unregister/1, whereis/1,
get_names/0]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
%%%%%%%%%%%%%%%%%
%%% INTERFACE %%%
%%%%%%%%%%%%%%%%%
start_link() ->
gen_server:start_link({local, ?MODULE}, ?MODULE, [], []).
stop() ->
gen_server:call(?MODULE, stop).
%% Give a name to a process
register(Name, Pid) when is_pid(Pid) ->
gen_server:call(?MODULE, {register, Name, Pid}).
%% Remove the name from a process
unregister(Name) ->
gen_server:call(?MODULE, {unregister, Name}).
%% Find the pid associated with a process
whereis(Name) -> ok.
%% Find all the names currently registered.
get_names() -> ok.
パブリックインターフェースでは、whereis/1 と get_names/0 のみが変更され、書き直されます。これは、前述のように、これらが単一読み取りの安全な操作であるためです。残りは、テーブルを所有するプロセスでシリアライズする必要があります。これが今のところAPIのすべてです。モジュール内部に進みましょう。
ETSテーブルを使用してデータを格納するため、そのテーブルを init 関数に入れるのが理にかなっています。さらに、whereis/1 および get_names/0 関数は(速度上の理由から)テーブルへのパブリックアクセスを提供するため、テーブルに名前を付けることは、外部からアクセスできるようにするために必要になります。プロセスに名前を付ける場合と同様にテーブルに名前を付けることで、IDを渡す必要はなく、関数に名前をハードコードできます。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%% GEN_SERVER CALLBACKS %%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
init([]) ->
?MODULE = ets:new(?MODULE, [set, named_table, protected]),
{ok, ?MODULE}.
次の関数は、register/2 で定義されているメッセージ {register, Name, Pid} を処理する handle_call/3 です。
handle_call({register, Name, Pid}, _From, Tid) ->
%% Neither the name or the pid can already be in the table
%% so we match for both of them in a table-long scan using this.
MatchSpec = ets:fun2ms(fun({N,P,_Ref}) when N==Name; P==Pid -> {N,P} end),
case ets:select(Tid, MatchSpec) of
[] -> % free to insert
Ref = erlang:monitor(process, Pid),
ets:insert(Tid, {Name, Pid, Ref}),
{reply, ok, Tid};
[{Name,_}|_] -> % maybe more than one result, but name matches
{reply, {error, name_taken}, Tid};
[{_,Pid}|_] -> % maybe more than one result, but Pid matches
{reply, {error, already_named}, Tid}
end;
これは、このモジュールで最も複雑な関数です。守るべき3つの基本的なルールがあります
- プロセスを2回登録することはできません
- 名前を2回取得することはできません
- プロセスはルール1と2に違反しない場合に登録できます
これは、上記のコードが何をしているかを示しています。fun({N,P,_Ref}) when N==Name; P==Pid -> {N,P} end から導出されたマッチ仕様は、登録しようとしている名前またはpidのいずれかに一致するエントリをテーブル全体から探します。一致するものがあれば、見つかった名前とpidの両方を返します。これは奇妙に思えるかもしれませんが、その後の case ... of のパターンを見ると、両方が必要な理由が理解できます。
最初のパターンは何も見つからなかったことを意味し、したがって挿入は問題ありません。登録したプロセスを監視し(失敗した場合に登録解除するため)、エントリをテーブルに追加します。登録しようとしている名前が既にテーブルにある場合、パターン [{Name,_}|_] が処理します。一致したのがPidだった場合は、パターン [{_,Pid}|_] が処理します。これが、両方の値が返される理由です。これにより、マッチ仕様でどちらが一致したかを気にせずに、後でタプル全体を照合するのが簡単になります。パターンが単に [Tuple] ではなく [Tuple|_] の形式であるのはなぜですか?説明は簡単です。Pidまたは同様の名前を探してテーブルを走査している場合、返されるリストが [{NameYouWant, SomePid},{SomeName,PidYouWant}] になる可能性があります。その場合、[Tuple] 形式のパターンマッチは、テーブルを担当するプロセスをクラッシュさせ、あなたの1日を台無しにします。
ああ、モジュールに -include_lib("stdlib/include/ms_transform.hrl"). を追加することを忘れないでください。そうしないと、fun2ms は奇妙なエラーメッセージで死んでしまいます。
** {badarg,{ets,fun2ms,
[function,called,with,real,'fun',should,be,transformed,with,
parse_transform,'or',called,with,a,'fun',generated,in,the,
shell]}}
これは、インクルードファイルを忘れたときに起こることです。警告したと思ってください。道を横断する前に見て、ストリームを交差させないで、インクルードファイルを忘れないでください。
次にやることは、プロセスを手動で登録解除するように要求された場合です。
handle_call({unregister, Name}, _From, Tid) ->
case ets:lookup(Tid, Name) of
[{Name,_Pid,Ref}] ->
erlang:demonitor(Ref, [flush]),
ets:delete(Tid, Name),
{reply, ok, Tid};
[] ->
{reply, ok, Tid}
end;
古いバージョンのコードを見たことがあるなら、これはまだ似ています。考え方は簡単です。監視参照(名前をルックアップ)を見つけて、監視をキャンセルし、エントリを削除して続行します。エントリがない場合は、とにかく削除したふりをして、誰もが満足します。ああ、私たちはなんて不正直なのでしょう。
次の部分はサーバーの停止についてです。
handle_call(stop, _From, Tid) ->
%% For the sake of being synchronous and because emptying ETS
%% tables might take a bit longer than dropping data structures
%% held in memory, dropping the table here will be safer for
%% tricky race conditions, especially in tests where we start/stop
%% servers a lot. In regular code, this doesn't matter.
ets:delete(Tid),
{stop, normal, ok, Tid};
handle_call(_Event, _From, State) ->
{noreply, State}.
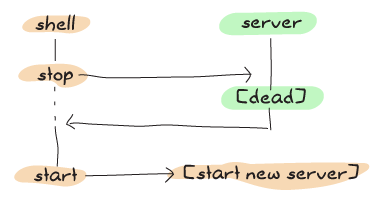
コード内のコメントにあるように、テーブルを無視してガーベジコレクションに任せるだけでも問題なかったでしょう。ただし、最後の章で作成したテストスイートは常にサーバーを起動および停止するため、遅延が少し危険になる可能性があります。これは、古いバージョンのプロセスがどのように見えるかを示すタイムラインです。
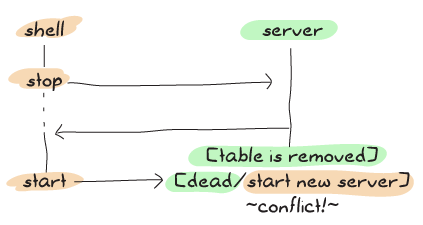
そして、これは新しいバージョンで時々起こることです。
上記のスキームを使用することで、コードの同期部分でより多くの作業を行うことで、エラーが発生する可能性を大幅に低くしています。
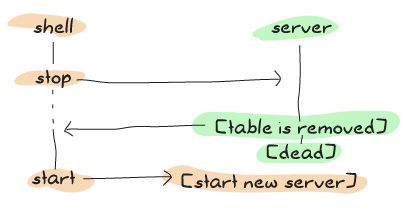
テストスイートを頻繁に実行する予定がない場合は、すべて無視してもかまいません。私は不快な驚きを避けるためにそれを示すことにしましたが、非テストシステムでは、このようなエッジケースはめったに発生しないはずです。
これが残りのOTPコールバックです。
handle_cast(_Event, State) ->
{noreply, State}.
handle_info({'DOWN', Ref, process, _Pid, _Reason}, Tid) ->
ets:match_delete(Tid, {'_', '_', Ref}),
{noreply, Tid};
handle_info(_Event, State) ->
{noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
監視していたプロセスの1つが停止したことを意味する DOWN メッセージの受信を除いて、どれも気にしません。それが起こった場合、メッセージにある参照に基づいてエントリを削除し、次に進みます。
code_change/3 は、実際には古い regis_server と新しい regis_server の間の移行として機能する可能性があることに気づくでしょう。この関数を実装することは、読者への練習問題として残されています。私は常に、解決策のない練習問題を読者に与える本を嫌っているので、私が他の作家のようにただの嫌な奴ではないように、少なくとも少しヒントを与えます。古いバージョンから2つの gb_trees のいずれかを取得し、gb_trees:map/2 または gb_trees イテレータを使用して、新しいテーブルにデータを入力してから次に進む必要があります。ダウングレード関数は、反対のことを行うことで記述できます。
残りの作業は、実装されていない2つのパブリック関数を修正することです。もちろん、%% TODO コメントを書いて、今日はこれで終わりにして、プログラマーであることを忘れるまで飲みに行くこともできますが、それは少し無責任でしょう。問題を修正しましょう。
%% Find the pid associated with a process
whereis(Name) ->
case ets:lookup(?MODULE, Name) of
[{Name, Pid, _Ref}] -> Pid;
[] -> undefined
end.
これは名前を探し、エントリが見つかったかどうかによって Pid または undefined を返します。ここでは、テーブル名として regis_server (?MODULE) を使用することに注意してください。それが、最初に保護して名前を付けた理由です。次のものについては
%% Find all the names currently registered.
get_names() ->
MatchSpec = ets:fun2ms(fun({Name, _, _}) -> Name end),
ets:select(?MODULE, MatchSpec).
fun2ms をもう一度使用して Name を照合し、それだけを保持します。テーブルから選択すると、リストが返され、必要な処理が行われます。
以上です! test/ でテストスイートを実行して、動作を確認できます。
$ erl -make ... Recompile: src/regis_server $ erl -pa ebin ... 1> eunit:test(regis_server). All 13 tests passed. ok
はい!これで、ETSに関してはかなり上手になったと言えるでしょう。
次にやるのが本当に良いことは何でしょう?実際にErlangの分散的な側面を探求することです。Erlangの獣を終える前に、もう少しねじれた方法で考えを曲げてみましょう。見てみましょう。