Distribunomicon
暗闇の中で一人
こんにちは!どうぞ座ってください。あなたを待っていました。初めてErlangのことを聞いたとき、あなたを引きつけたのは2つか3つの特徴だったでしょう。Erlangは関数型言語であり、並行処理に優れたセマンティクスを持ち、分散処理をサポートしています。私たちはすでに最初の2つの属性を見てきましたし、おそらく予想していなかった12個以上の属性を探求する時間を費やしてきました。そして今、最後の大きなポイントである分散処理について見ていきます。
ローカルで動作させることができないのに分散化しても意味がないため、ここまで来るのにかなりの時間を費やしました。私たちはついにその段階に達し、ここまで来るために長い道のりを歩んできました。Erlangの他のほとんどの機能と同様に、言語の分散レイヤーは、最初に耐障害性を提供するために追加されました。単一のコンピューター上で実行されているソフトウェアは、常にその単一のコンピューターが故障してアプリケーションがオフラインになるリスクがあります。多くのコンピューター上で実行されているソフトウェアは、ハードウェアの故障処理を容易にします。ただし、それはアプリケーションが正しく構築されている場合のみです。アプリケーションが多くのサーバー上で実行されているにもかかわらず、1つのサーバーがダウンしても対処できない場合、耐障害性に関するメリットはありません。

そうです、分散プログラミングは、モンスターだらけの暗闇の中に一人ぼっちにされるようなものです。恐ろしいものです。何をすべきか、何が襲ってくるのかわかりません。悪いニュース:分散Erlangは、あなたを依然として暗闇の中に一人ぼっちに残し、恐ろしいモンスターと戦うようにします。それはあなたのためにその種の難しい仕事は何もしてくれません。良いニュース:ポケットの小銭と悪い狙いだけでモンスターを倒すのではなく、Erlangは懐中電灯、マチェーテ、そして自信を高めるためのかなりかっこいい口ひげを与えてくれます(女性読者にも当てはまります)。
それはErlangの書き方によるものではなく、分散ソフトウェアの本質によるものです。Erlangは分散の基本的なビルディングブロックを記述します。つまり、多くのノード(仮想マシン)がお互いに通信する方法、通信におけるデータのシリアル化とデシリアル化、複数のプロセスという概念を多くのノードに拡張する方法、ネットワーク障害を監視する方法などです。しかし、「何が起こったのか」などのソフトウェア固有の問題に対する解決策は提供しません。
これは、OTPで以前に見た標準的な「ツール、ソリューションではない」アプローチです。フル機能のソフトウェアやアプリケーションを得ることはめったにありませんが、システムを構築するための多くのコンポーネントを得ることができます。システムの一部が稼働または停止したことを教えてくれるツール、ネットワーク上でたくさんの作業を行うツールはありますが、あなたのために物事を修正してくれる魔法の弾丸はほとんどありません。
これらのツールでどのような柔軟性があるか見てみましょう。
これが私のブームスティックだ
暗闇の中のこれらのモンスターすべてに対処するために、私たちは非常に便利なものを与えられました。それは、非常に完全なネットワーク透過性です。
稼働しており、他の仮想マシンに接続する準備ができているErlang仮想マシンのインスタンスは、ノードと呼ばれます。一部の言語やコミュニティではサーバーをノードと見なしますが、Erlangでは各VMがノードです。したがって、単一のコンピューター上で50個のノードを実行したり、50台のコンピューター上で50個のノードを実行したりできます。どちらでも問題ありません。
ノードを起動すると、名前を付け、EPMD(Erlang Port Mapper Daemon)と呼ばれるアプリケーションに接続します。これは、Erlangクラスタの一部である各コンピューターで実行されます。EPMDは、ノードが自身を登録し、他のノードに連絡し、名前の競合がある場合は警告する名前サーバーとして機能します。
この時点から、ノードは別のノードへの接続を確立することを決定できます。そうすると、両方のノードは自動的に互いを監視し始め、接続が切断されたか、ノードが消えたかどうかを知ることができます。さらに重要なのは、すでに接続されたノードのグループの一部である別のノードに新しいノードが参加すると、新しいノードはグループ全体に接続されることです。
ゾンビの発生時の多くの生存者のアイデアを例に、Erlangノードがどのように接続を設定するかを示します。ゾーイ、ビル、リック、ダリルがいます。ゾーイとビルはお互いを知っていて、トランシーバーで同じ周波数で通信しています。リックとダリルはそれぞれ単独でいます。
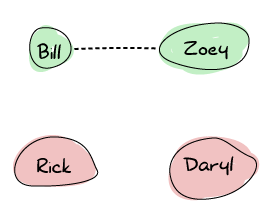
さて、リックとダリルが生存者キャンプへの途中で出会ったとしましょう。彼らはトランシーバーの周波数を共有し、再び別れる前に互いに最新情報を維持できます。
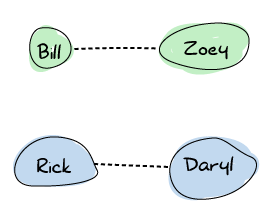
ある時点で、リックはビルに会います。どちらもそれを非常に喜んでおり、周波数を共有することにしました。この時点で、接続が広がり、最終的なグラフは次のようになります。
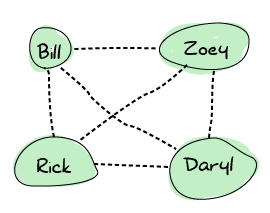
つまり、どの生存者も直接他の生存者に連絡できます。これは、生存者の死亡が発生した場合、誰も孤立しないため便利です。Erlangノードはまさにこの方法で設定されます。すべてがすべてに接続されます。
クールドリンクを飲みすぎないでください
この方法では、耐障害性の理由から良いものですが、スケーラビリティにかなり悪い欠点があります。接続数と必要なチャターの量のために、Erlangクラスタの一部である数百ものノードを持つことは困難になります。実際、接続するノードごとに1つのポートが必要です。
Erlangを使用してそのような重い設定を行う予定がある場合は、この章で、なぜそのような状況になっているのか、そして可能であれば問題を回避するために何ができるのかについて説明していますので、読んでみてください。
ノードが接続されると、完全に独立したままになります。独自ののプロセスレジストリ、独自のETSテーブル(テーブルには独自の名称)、ロードするモジュールは互いに独立しています。クラッシュした接続されたノードは、接続されているノードをダウンさせません。
接続されたノードは、メッセージの交換を開始できます。Erlangの分散モデルは、ローカルプロセスがリモートプロセスに連絡して通常のメッセージを送信できるように設計されています。何も共有されておらず、すべてのプロセスレジストリが一意である場合、これはどのように可能でしょうか?分散の具体的な内容について後ほど説明しますが、特定のノードで登録されているプロセスにアクセスする方法があります。そこから最初のメッセージを送信できます。
Erlangメッセージは、透過的な方法で自動的にシリアル化およびデシリアル化されます。pidを含むすべてのデータ構造は、リモートとローカルで同じように機能します。つまり、ネットワークを介してpidを送信し、メッセージを送信するなどして通信できます。さらに良いことに、pidにアクセスできれば、ネットワークを介してリンクとモニターを設定できます!
Erlangはすべてを非常に透過的に処理しているのであれば、なぜ私はマチェーテ、懐中電灯、そして口ひげしか与えられていないと言っているのでしょうか?
分散コンピューティングの誤謬
マチェーテは特定の種類のモンスターを殺すためにあるように、Erlangのツールは特定の種類の分散コンピューティングのみを処理するためにあるものです。Erlangが提供するツールを理解するには、まず分散の世界にどのような状況が存在するのか、そしてErlangが耐障害性を提供するためにどのような仮定をしているのかを理解する必要があります。
非常に賢い人々は、過去数十年間、分散コンピューティングで何がうまくいかないのかを分類するために時間を費やしてきました。彼らは、後で問題を引き起こす可能性のある、人々がする8つの主要な仮定を考え出しました。Erlangの設計者もさまざまな理由でそのうちのいくつかをしました。
ネットワークは信頼できる
分散コンピューティングの最初の誤謬は、アプリケーションをネットワーク上に分散できると仮定することです。それは少し奇妙に聞こえるかもしれませんが、ネットワークは厄介な理由でダウンすることがたくさんあります。電力障害、ハードウェアの故障、誰かがコードを踏んだこと、他の次元に続く渦がミッションクリティカルなコンポーネントを飲み込むこと、ヘッドクラップの蔓延、銅の盗難などです。
したがって、犯しやすい最大のエラーの1つは、リモートノードに到達してそれらと通信できると考えることです。これは、より多くのハードウェアを追加して冗長性を高めることで、あるハードウェアが故障した場合でもアプリケーションにアクセスできるようになることで、ある程度対処できます。もう1つの方法は、メッセージとリクエストの損失を受け入れ、応答不能になる準備をすることです。これは、独自のソフトウェアスタックが正常に機能している間、何らかのサードパーティサービスに依存していて、それがなくなってしまった場合に特に当てはまります。
Erlangにはこれに対処するための特別な対策はありません。これは通常、決定がアプリケーション固有のものであるためです。結局のところ、特定のコンポーネントの重要性を誰が知っているでしょうか?それでも、あなたは完全に一人ではありません。分散Erlangノードは、他のノードが切断されたこと(または応答不能になったこと)を検出できます。ノードを監視するための特定の関数があり、リンクとモニターも接続解除時にトリガーされます。
それでも、この場合、Erlangが持つ最大の強みは、非同期通信モードです。非同期的にメッセージを送信し、うまくいった場合に返信を送信するように開発者を強制することにより、Erlangはすべてのメッセージパッシングアクティビティが直感的に障害を処理するように促します。何らかのネットワーク障害のために消えたノード上にいるプロセスと話している場合、ローカルクラッシュと同じように自然に処理します。これは、Erlangがうまくスケールすると(パフォーマンスでのスケーリングだけでなく、設計でのスケーリングでも)言われる多くの理由の1つです。
クールドリンクを飲みすぎないでください
ノード間でのリンクと監視は危険な場合があります。ネットワーク障害の場合、すべてのリモートリンクとモニターが同時にトリガーされます。これにより、さまざまなプロセスに数千ものシグナルとメッセージが生成され、システムに重い予期せぬ負荷がかかります。
信頼性の低いネットワークに備えることは、突然の障害に備え、システムがシステムの一部が突然消えても機能しなくなるようにすることを意味します。
レイテンシはない
一見すると優れた分散システムの両刃の側面の1つは、行っている関数呼び出しがリモートであるという事実を隠してしまうことが多いことです。一部の関数呼び出しは非常に高速であると予想しますが、ネットワークを介して行うのはまったく同じではありません。ピッツェリア内からピザを注文することと、別の都市から自宅にピザを配達してもらうことの違いです。常に基本的な待ち時間がありますが、一方の場合、ピザは時間がかかりすぎたため冷たく配達される可能性があります。
ネットワーク通信により、非常に小さなメッセージでも時間がかかると忘れると、常に非常に高速な結果を期待する場合、高価なエラーになる可能性があります。Erlangのモデルはそこで私たちをうまく扱います。分離されたプロセス、非同期メッセージ、タイムアウト、およびプロセスの失敗の可能性を常に考えてローカルアプリケーションを設定する方法により、分散化するために必要な適応はほとんどありません。タイムアウト、リンク、モニター、および非同期パターンは同じままで、依然として信頼性があります。私たちは最初からその種類の問題を常に期待していたため、Erlangは暗黙的にレイテンシがないと仮定しません。
ただし、設計でその仮定をして、現実的に可能なよりも速く返信を期待する可能性があります。注意深く見ておいてください。
帯域幅は無限大です
ネットワーク転送は常に高速化されており、一般的に言って、ネットワークを介して転送される各バイトのコストは時間とともに安価になりますが、大量のデータを送信することが簡単で簡単だと仮定するのは危険です。
一般的に、ローカルにアプリケーションを構築する方法により、Erlangではこれに関する問題はあまりありません。覚えておいてください、良いトリックの1つは、新しい状態を移動するのではなく、何が起こっているかについてのメッセージを送信することです(「プレイヤーXがアイテムYを見つけた」ではなく、プレイヤーXのインベントリ全体を何度も送るのではなく)。
何らかの理由で大きなメッセージを送信する必要がある場合、非常に注意が必要です。Erlangの分散と通信は、多くのノードにわたって動作するため、大きなメッセージに特に敏感です。2つのノードが接続されている場合、それらの間の通信はすべて単一のTCP接続で行われる傾向があります。(ネットワークをまたいだとしても)2つのプロセス間のメッセージの順序を維持したいという一般的な要件から、メッセージは接続上で順次送信されます。つまり、非常に大きなメッセージがあると、他のすべてのメッセージのチャネルをブロックする可能性があります。
さらに悪いことに、Erlangは「ハートビート」と呼ばれるものを送信することで、ノードがアクティブかどうかを認識します。ハートビートは、2つのノード間で定期的に送信される小さなメッセージで、「まだ生きています。続行してください!」という意味です。まるで私たちのゾンビサバイバーたちが定期的にメッセージで互いに確認し合っているようなものです。「ビル、そこにいる?」。そして、ビルが返答しないと、彼は死んでいる(または電池が切れている)と仮定し、将来の通信は届かなくなります。いずれにせよ、ハートビートは通常のメッセージと同じチャネルで送信されます。
問題は、大きなメッセージがハートビートを遅らせる可能性があることです。大きなメッセージが多すぎてハートビートが長期間遅れると、いずれかのノードは最終的に相手が応答していないと判断し、互いに接続を切断します。これは深刻な問題です。いずれにしても、これを防ぐための優れたErlang設計の教訓は、メッセージを小さく保つことです。そうすることで、すべてが改善されます。
ネットワークは安全です
分散システムになると、すべてが安全であり、受信したメッセージを信頼できると考えることは非常に危険な場合があります。予期しない人物がメッセージを作成して送信したり、パケットを傍受して変更したり(または機密データを見たり)、最悪の場合、アプリケーションや実行されているシステムを乗っ取ったりするといった単純なことです。
分散Erlangの場合、残念ながらこれは当初から仮定されていました。Erlangのセキュリティモデルは以下のとおりです。
*このスペースは意図的に空欄になっています*
はい。これは、Erlangの分散が当初、コンポーネントのフォールトトレランスと冗長性を目的としていたためです。電話交換機やその他の電気通信アプリケーションで使用されていた初期の頃、Erlangはしばしば非常に奇妙な場所で動作するハードウェアに展開されていました—非常に離れた場所、奇妙な状況(エンジニアが湿った地面を避けるためにサーバーを壁に取り付けたり、ハードウェアを最適な温度で動作させるために森の中にカスタムの暖房システムを設置したりする必要がありました)。これらの場合、メインのハードウェアと同じ物理的な場所にフェールオーバーハードウェアがありました。これは分散Erlangが実行される場所であり、Erlangの設計者が安全なネットワークを想定していた理由を説明しています。
残念ながら、これは現代のErlangアプリケーションを異なるデータセンターにまたがってクラスタリングすることはほとんどできないことを意味します。実際、そうすることは推奨されません。ほとんどの場合、システムは通常単一の場所に配置された、より小さく、隔離されたErlangノードのクラスタを多くベースにする必要があります。より複雑なものは開発者に任せる必要があります。SSLに切り替えたり、独自の高度な通信レイヤーを実装したり、安全なチャネルを介してトンネリングしたり、ノード間の通信プロトコルを再実装したりすることです。これを行う方法については、ERTSユーザーガイドのErlang配布のための代替キャリアの実装方法に記載されています。分散プロトコルに関する詳細については、分散プロトコルに記載されています。これらの場合でも、非常に注意する必要があります。分散ノードの1つにアクセス権を持つ人物は、すべてのノードにアクセスでき、任意のコマンドを実行できるからです。
トポロジーは変化しません
多くのサーバーで実行するように設計された分散アプリケーションを最初に設計する場合、特定の数のサーバーと、おそらく特定のホスト名のリストを念頭に置いておく可能性があります。特定のIPアドレスを考慮して設計することもあります。これは間違いです。ハードウェアは故障し、運用担当者はサーバーを移動し、新しいマシンが追加され、一部が削除されます。ネットワークのトポロジーは常に変化します。アプリケーションがこれらのトポロジの詳細をハードコードして動作する場合、ネットワークのこのような変化に容易に対処できません。
Erlangの場合、そのような明示的な仮定はありません。しかし、アプリケーション内部に忍び込むことは非常に簡単です。Erlangノードにはすべて名前とホスト名があり、常に変化する可能性があります。Erlangプロセスでは、プロセスの名前だけでなく、クラスタ内の現在の場所についても考える必要があります。名前とホストの両方をハードコードすると、次の障害時に問題が発生する可能性があります。ただし、後でノード名やトポロジー全般を無視しながら、特定のプロセスを見つけることができるいくつかの興味深いライブラリについて説明するので、あまり心配する必要はありません。
管理者は1人だけです
これは、言語またはライブラリの分散レイヤーでは準備できないものです。この誤謬の考え方は、ソフトウェアとそのサーバーには常に1人の主要なオペレーターがいるとは限らないということです。1人のオペレーターしかいないかのように設計されている場合でもです。単一コンピューター上に多くのノードを実行することにした場合、この誤謬を気にする必要はほとんどありません。ただし、異なる場所全体で実行したり、サードパーティがコードに依存したりする場合、注意する必要があります。
注意すべき点には、システムの問題を診断するためのツールを他の人に提供することが含まれます。VMを手動で操作できる場合、Erlangはデバッグが比較的簡単です—必要に応じて、コードをオンザフライでリロードすることもできます。ターミナルにアクセスできず、ノードの前に座ることができない人は、操作するために異なる機能を必要とします。
この誤謬のもう1つの側面は、サーバーの再起動、データセンター間のインスタンスの移動、ソフトウェアスタックの一部をアップグレードすることは、必ずしも1人または1つのチームだけが制御するものではないということです。非常に大規模なソフトウェアプロジェクトでは、実際には多くのチーム、または多くの異なるソフトウェア会社が、より大きなシステムの異なる部分を担当する可能性があります。
ソフトウェアスタックのプロトコルを作成している場合、ユーザーやパートナーがコードをアップグレードする速度に応じて、そのプロトコルの多くのバージョンを処理できる必要がある場合があります。プロトコルは、最初からバージョン情報を含んでいるか、ニーズに応じてトランザクションの途中で変更できる場合があります。他に何が間違っている可能性があるかをもっと考えられると思います。
転送コストはゼロです
これは2面的な仮定です。1つは時間という観点からのデータ転送コストに関連し、もう1つは金銭という観点からのデータ転送コストに関連します。
最初のケースでは、データのシリアル化などの処理はほぼ無料であり、非常に高速であり、大きな役割を果たさないことを前提としています。実際には、より大きなデータ構造は、小さなデータ構造よりもシリアル化に時間がかかり、ワイヤの反対側で逆シリアル化される必要があります。これは、ネットワークを介して何を転送する場合でも当てはまります。小さなメッセージは、この影響が目立たなくなるのに役立ちます。
転送コストがゼロであると仮定することの2番目の側面は、データの転送にかかるコストに関係しています。最新のサーバースタックでは、メモリ(RAMとディスクの両方)は、帯域幅のコストと比較して安価であることが多く、ネットワーク全体を所有しない限り、継続的に支払う必要があります。この場合、小さなメッセージで要求数を減らすことに最適化することは有益です。
Erlangは、初期のユースケースのために、ノード間でメッセージを圧縮するための特別な配慮はされていません(ただし、そのための関数は既に存在します)。代わりに、元の設計者は、必要であれば独自の通信レイヤーを実装できるように選択しました。したがって、小さなメッセージを送信し、データ転送のコストを最小限に抑えるための他の対策を講じる責任はプログラマーにあります。
ネットワークは同種です
この最後の仮定は、ネットワーク化されたアプリケーションのすべてのコンポーネントが同じ言語を話すか、一緒に動作するために同じ形式を使用することを考えていることです。
私たちのゾンビサバイバーにとって、これは、すべてのサバイバーが計画を立てるときに常に英語(または上手な英語)を話すとは限らないこと、または単語が異なる人に異なる意味を持つことを前提としないという問題です。

プログラミングの観点から、これは通常、クローズドスタンダードに依存しないことですが、代わりにオープンスタンダードを使用するか、いつでもプロトコルを切り替える準備をすることです。Erlangの場合、分散プロトコルは完全に公開されていますが、Erlangノードはすべて、それらと通信する人が同じ言語を話すことを前提としています。Erlangクラスタに統合しようとする外部の人々は、Erlangのプロトコルを学習するか、ErlangアプリケーションにXML、JSONなどに対する何らかの変換レイヤーが必要になります。
アヒルのように鳴き、アヒルのように歩くなら、それはアヒルに違いない。そのため、Cノードのようなものがあります。Cノード(またはC以外の言語のノード)は、任意の言語とアプリケーションがErlangのプロトコルを実装し、クラスタ内のErlangノードであるふりをできるという考えに基づいています。
データ交換のもう1つのソリューションは、BERTまたはBERT-RPCと呼ばれるものを使用することです。これはXMLやJSONのような交換形式ですが、Erlang外部項形式と同様のものとして指定されています。
要約すると、常に以下の点に注意する必要があります。
- ネットワークが信頼できることを想定すべきではありません。Erlangには、何か問題が発生したことを検出する機能以外は、特別な対策はありません(ただし、これは機能としてそれほど悪くはありません)。
- ネットワークは時々遅くなる可能性があります。Erlangは非同期メカニズムを提供し、それを認識していますが、アプリケーションがこれと矛盾してそれを台無しにしないように注意する必要があります。
- 帯域幅は無制限ではありません。小さく、記述的なメッセージはこれの尊重に役立ちます。
- ネットワークは安全ではなく、Erlangはデフォルトでこれに対して何も提供しません。
- ネットワークのトポロジーは変更される可能性があります。Erlangでは明示的な仮定は行われませんが、物事の場所や名前の付け方について仮定する可能性があります。
- あなた(またはあなたの組織)が物事の構造を完全に制御することはめったにありません。システムの一部は古くなっている可能性があり、異なるバージョンを使用しており、予想しないときに再起動または停止される可能性があります。
- データの転送にはコストがかかります。繰り返しますが、小さく短いメッセージが役立ちます。
- ネットワークは異種です。すべてが同じではなく、データ交換は十分に文書化された形式に依存する必要があります。
注:分散コンピューティングの誤謬は、Arnon Rotem-Gal-Ozによる分散コンピューティングの誤謬の説明で紹介されました。
死んでいるか、生きているか
分散コンピューティングの誤謬を理解することで、なぜ暗闇の中でモンスターと戦っているのか(しかし、より良いツールを使って)が部分的に説明されたはずです。まだ多くの問題と私たちがするべきことが残っています。それらの多くは、上記の誤謬に関する注意が必要な設計上の決定(小さなメッセージ、通信の削減など)です。最も問題のある問題は、ノードが死んだり、ネットワークが信頼できなくなったりすることに関係しています。(それらに連絡できない限り)何かが死んでいるのか生きているのかを知る良い方法がないため、これは特に厄介です。
私たちの4人のゾンビアポカリプスサバイバーであるビル、ゾーイ、リック、ダリルに戻りましょう。彼らは安全な家で出会い、そこで数日間休息し、見つけることができるあらゆる缶詰を食べて過ごしました。しばらくして、彼らは出て行き、より多くの資源を見つけるために町中に分散する必要がありました。彼らは、いる小さな町の限界にある小さなキャンプに集合場所を設定しました。
遠征中、彼らはトランシーバーで連絡を取り合っています。彼らは発見したものを発表し、道をクリアにし、新しいサバイバーを見つけることもあります。
さて、安全ハウスと待ち合わせ地点の間のある時点で、リックが仲間と連絡を取ろうとしたとしましょう。彼はビルとゾーイに電話をかけ、話をすることができましたが、ダリルには連絡が取れませんでした。ビルとゾーイも彼に連絡を取ることができません。問題は、ダリルがゾンビに食い殺されたのか、バッテリーが切れたのか、寝ているのか、単に地下にいるのかを知る方法が全くないということです。
グループは、彼を待ち続けるか、しばらく呼びかけ続けるか、彼が死亡したと仮定して先に進むかを決定しなければなりません。
分散システムのノードでも同じジレンマが存在します。ノードが応答しなくなった場合、ハードウェアの故障で消滅したのでしょうか?アプリケーションがクラッシュしたのでしょうか?ネットワークに輻輳があるのでしょうか?ネットワークがダウンしているのでしょうか?場合によっては、アプリケーションがもはや実行されておらず、そのノードを無視して作業を続けることができます。他の場合では、アプリケーションはまだ孤立したノード上で実行されており、そのノードの観点からは、他のものはすべて死んでいます。
Erlangは、到達不能なノードを死んでいるノードと見なし、到達可能なノードを生きているノードと見なすというデフォルトの決定を行いました。これは、壊滅的な障害に非常に迅速に反応したい場合に理にかなった悲観的なアプローチであり、ネットワークはシステムのハードウェアやソフトウェアよりも一般的に故障する可能性が低いと仮定しています。これは、Erlangが元々どのように使用されていたかを考えると理にかなっています。楽観的なアプローチ(ノードはまだ生きていると仮定する)は、ネットワークはハードウェアやソフトウェアよりも故障する可能性が高いと仮定するため、クラッシュ関連の対策を遅らせる可能性があり、そのためクラスタは切断されたノードの再統合をより長く待つことになります。
これは疑問を提起します。悲観的なシステムでは、死んだと思っていたノードが突然戻ってきて、実際には死んでいなかったことが判明した場合、どうなるのでしょうか?私たちは、クラスタからあらゆる面で(データ、接続など)隔離され、独自の生命を持っていた「生きている死者のノード」に不意を突かれます。非常に厄介なことが起こる可能性があります。
2つの異なるデータセンターに2つのノードを持つシステムがあると想像してみましょう。そのシステムでは、ユーザーはアカウントにお金を保有しており、全額が各ノードに保持されています。各トランザクションは、その後データを他のすべてのノードに同期します。すべてのノードが正常に動作している場合、ユーザーはアカウントが空になるまでお金を使い続け、その後は何も販売できなくなります。
ソフトウェアは正常に動作していますが、ある時点で、ノードの1つが他のノードから切断されます。相手が生きているのか死んでいるのかを知る方法はありません。私たちにとって、両方のノードはまだ一般からリクエストを受け取っている可能性がありますが、互いに通信することはできません。
2つの一般的な戦略があります。すべてのトランザクションを停止するか、停止しないかです。最初の戦略を選ぶリスクは、製品が利用できなくなり、お金を失うことです。2番目の戦略のリスクは、アカウントに1000ドルあるユーザーが、合計2000ドルのトランザクションを受け入れることができる2つのサーバーを持つことです!何をするにしても、正しく行わなければお金を失うリスクがあります。
サーバー間でデータを失うことなく、ネットワーク分割中にアプリケーションの可用性を維持することで、問題を完全に回避する方法はないでしょうか?

私のもう一つの帽子は定理です
前の質問への簡単な答えは「いいえ」です。ネットワーク分割中にアプリケーションを同時に稼働させ、かつ正確に保つ方法は残念ながらありません。
この考え方は、CAP定理として知られています(パーティション耐性を犠牲にすることはできませんも興味深いでしょう)。CAP定理はまず、存在するすべての分散システムには3つのコア属性があることを述べています。それは、一貫性(C)、可用性(A)、そしてパーティション耐性(P)です。
一貫性
前の例では、一貫性とは、2つであろうと1000であろうと、ノードの数に関わらず、システムが特定の時点でアカウント内の正確な金額を表示できる能力のことです。これは通常、トランザクションを追加する(すべてのノードが変更を行うことに単一の単位として同意するまでデータベースへの変更を行わない)または同等のメカニズムを追加することで行われます。
定義上、一貫性とは、多くのノードにまたがっても、すべてのアクションが単一の不可分なブロックとして完了したように見えるということです。これは時間的な問題ではなく、同じデータ片に対する2つの異なる操作が、これらの操作中にシステムによって報告される複数の異なる値を与えるような方法でそれらを変更しないという点です。データ片を変更することができ、他のアクタがあなたと同じ時間にそれをいじることであなたの邪魔をすることを心配する必要がないようにする必要があります。
可用性
可用性とは、システムにデータの一部を要求した場合、応答を得ることができるということです。応答が得られない場合、システムは利用できません。 「申し訳ありませんが、死んでいるため結果を判断できません」という応答は、真の応答ではなく、単なる悲しい言い訳です。この応答には、まったく応答がない場合よりも役に立つ情報はありません(ただし、学者の間ではこの問題について意見が分かれています)。
注:CAP定理における重要な考慮事項は、可用性は死んでいないノードにのみ関心があるということです。死んでいるノードは、そもそもクエリを受信できないため、応答を送信できません。これは、依存するものがなくなったため応答を送信できないノードとは異なります!ノードがリクエストを受け取ったり、データを変更したり、誤った結果を返したりできない場合、厳密には正確性の点でシステムのバランスに対する脅威ではありません。クラスタの残りは、ノードが起動し、同期できるようになるまで、より多くの負荷を処理する必要があります。
パーティション耐性
これがCAP定理の難しい部分です。パーティション耐性とは、通常、その一部が互いに通信できなくなった場合でも、システムが動作し続け(そして有用な情報を含む)ことができることを意味します。パーティション耐性のポイントは、システムがコンポーネント間でメッセージが失われる可能性がある状況でも動作できることです。定義はやや抽象的で、開かれています。その理由を見ていきましょう。
CAP定理は基本的に、あらゆる分散システムにおいて、CAPの2つしか持つことができないと規定しています。CA、CP、またはAPのいずれかです。すべてを同時に持つことは不可能です。これは良いニュースでもあり、悪いニュースでもあります。悪いニュースは、ネットワーク障害が発生した場合でも、常にすべてがうまくいくとは限らないということです。良いニュースは、これが定理であるということです。顧客が3つすべてを提供するように求めた場合、それは文字通り不可能であると伝えることができ、CAP定理とは何かを説明する以外の時間をあまり無駄にする必要がありません。
3つの可能性のうち、通常無視できるのはCA(一貫性+可用性)のアイデアです。その理由は、これを本当に望むのは、ネットワークが絶対に故障しないと主張する、または故障するとしても原子単位で行われる(何かが故障すると、すべてが同時に故障する)と主張するような場合に限られるからです。
誰かが決して故障しないネットワークとハードウェアを発明するか、システムのすべてのパーツを1つが故障した場合に同時に故障させる方法を見つけるまで、故障は選択肢として残ります。CAP定理の組み合わせは、APまたはCPの2つだけです。ネットワーク分割によって分離されたシステムは、可用性または一貫性を維持できますが、両方同時に維持することはできません。
注:一部のシステムは、「A」または「C」のどちらも選択しません。高性能の場合、スループット(まったく応答できるクエリの数)やレイテンシ(クエリの応答速度)などの基準により、CAP定理が2つの属性(CA、CP、またはAP)だけでなく、2つ以下の属性についても考慮される場合があります。
生き残ったグループは時が経ち、しばらくの間、アンデッドのグループを撃退しました。弾丸は脳を貫き、野球のバットは頭蓋骨を砕き、噛まれた人々は後方に残されました。ビル、ゾーイ、リック、そしてダリルのバッテリーは最終的に消耗し、彼らは通信できなくなりました。幸いなことに、彼らはゾンビサバイバルに夢中になっているコンピューター科学者とエンジニアで構成された2つのサバイバーコロニーを見つけました。コロニーのサバイバーたちは分散プログラミングの概念に慣れており、自家製プロトコルを使用して光信号と鏡で通信することに慣れていました。
ビルとゾーイは「チェーンソー」コロニーを見つけ、リックとダリルは「クロスボウ」キャンプを見つけました。サバイバーたちはそれぞれのコロニーで最新の参加者だったため、彼らはしばしば野生に出かけ、食料を探し、周囲に近づきすぎるゾンビを殺す任務を与えられ、残りの人々はvim対emacsの長所について議論していました。これは、完全なゾンビ黙示録の後でも死なない唯一の戦争でした。
彼らの100日目に、4人のサバイバーは、各コロニーのために商品を交換するために、キャンプの半ばで会うように送られました。
出発前に、チェーンソーとクロスボウのコロニーによって待ち合わせ地点が決定されました。目的地または待ち合わせ時間が変更される場合、リックとダリルはクロスボウコロニーにメッセージを送信でき、ゾーイとビルはチェーンソーコロニーにメッセージを送信できます。その後、各コロニーは情報をもう一方のコロニーに伝え、もう一方のサバイバーに変更を転送します。
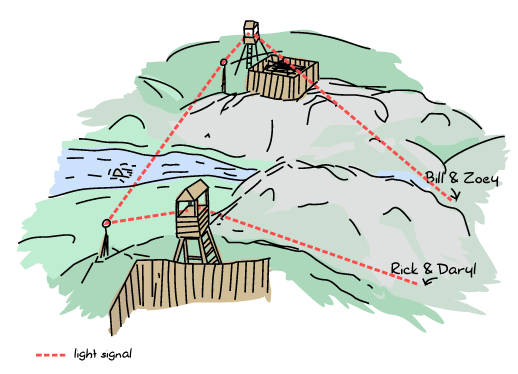
これを踏まえ、4人のサバイバー全員が日曜日の早朝に出発し、金曜日の夜明け前に会うために徒歩で長い旅に出かけました。(かなり前から生きていた死んだ人々との時折の戦闘を除いて)すべてが順調に進みました。
残念ながら、水曜日に、激しい雨とゾンビの活動の増加により、ビルとゾーイは離れ離れになり、迷子になり、遅れてしまいました。新しい状況は、少しこんな感じでした。
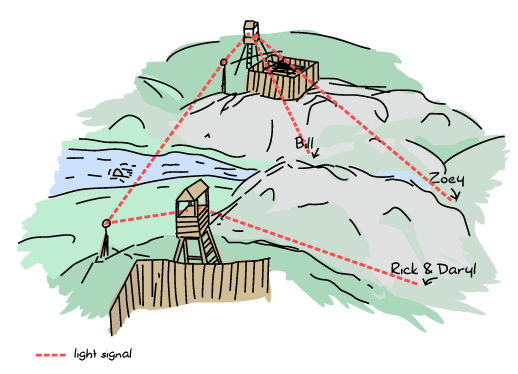
さらに悪いことに、雨の後、2つのコロニーの間の通常は晴れ渡っていた空が霧になり、チェーンソーのコンピューター科学者たちはクロスボウの人々と通信できなくなりました。
ビルとゾーイはコロニーに問題を伝え、新しい待ち合わせ時間を設定するよう依頼しました。霧がなければ問題なかったでしょうが、今ではネットワーク分割に相当する状況になっています。
両方のキャンプが一貫性+パーティション耐性の方法で動作する場合、ゾーイとビルは新しい待ち合わせ時間を設定できなくなります。CPアプローチは通常、データの変更を停止して一貫性を維持することに重点を置いており、すべてサバイバーは時々それぞれのキャンプに日付を問い合わせることができます。彼らは変更する権利を拒否されるだけです。これを行うことで、一部のサバイバーが計画された待ち合わせ時間を混乱させることがなくなることが保証されます。連絡が途絶えた他のサバイバーは、状況に関係なく、時間通りにそこで会うことができます。
両方のキャンプが代わりに可用性+パーティション耐性を選択した場合、サバイバーは待ち合わせ日を自由に変更できたでしょう。パーティションの両側には、待ち合わせデータの独自のバージョンがあります。したがって、ビルが金曜日の夜の新しい待ち合わせを呼び出した場合、一般的な状態は次のようになります。
Chainsaw: Friday night Crossbow: Friday before dawn
分割が続く限り、ビルとゾーイはチェーンソーからのみ情報を入手し、リックとダリルはクロスボウからのみ情報を入手します。これにより、サバイバーの一部が必要に応じて再編成することができます。
ここで興味深い問題は、分割が解決され(そして霧が晴れると)、データの異なるバージョンをどのように処理するかです。CPアプローチではこれは非常に簡単です。データは変更されていないため、何もする必要はありません。APアプローチはより柔軟性があり、解決すべき問題が多くなります。通常、さまざまな戦略が用いられます。
- 最終書き込み優先は、最後の更新内容を保持するコンフリクト解決方法です。分散環境では、タイムスタンプがずれていたり、まったく同時に発生することがあるため、これは厄介になる可能性があります。
- 勝者はランダムに選ぶことができます。
- コンフリクトを減らすためのより高度な方法には、最終書き込み優先などの時間ベースの方法がありますが、相対時計を使用します。相対時計は絶対的な時間値ではなく、誰かがファイルを修正するたびに増分する値を使用します。これについて詳しく知りたい場合は、Lamport時計またはベクトル時計について調べてください。
- コンフリクトの処理方法を選択する責任は、アプリケーション(または私たちの場合、サバイバー)に委ねることができます。受信側は、競合するエントリのうちどれが正しいかを選択する必要があります。これは、SVN、Mercurial、Gitなどでソースコードの競合をマージする場合に起こることと少し似ています。
どちらが良いのでしょうか?私の説明では、完全にAPであるか完全にCPであるかのどちらかを選択できると信じ込まされてきました。オン/オフスイッチのようなものです。現実世界では、クォーラムシステムなど、この「はい/いいえ」の質問をダイヤルに変えて、必要な整合性のレベルを選択できます。
クォーラムシステムは、いくつかの非常にシンプルなルールで機能します。システムにはN個のノードがあり、データの変更を可能にするには、そのうちM個のノードが合意する必要があります。整合性要件が比較的低いシステムでは、変更を行うためにノードのわずか15%しか利用できないように要求できます。これは、分割が発生した場合でも、ネットワークの小さな断片がデータの変更を続けられることを意味します。整合性評価が高く、ノードの75%に設定されている場合、変更を行うには、システムのより大きな部分が存在する必要があります。この状況では、いくつかのノードが孤立している場合、それらはデータを変更する権利を持ちません。ただし、相互接続されたシステムの大部分は正常に機能します。
Mの値(必要なノードの数)をN(ノードの総数)まで変更することで、完全に整合性の取れたシステムにすることができます。Mに1という値を与えると、整合性の保証がない完全にAPシステムになります。
さらに、クエリごとにこれらの値を調整できます。重要性の低いもの(誰かがログインしただけ!)に関するクエリは整合性要件を低く設定でき、在庫や金銭に関するものはより高い整合性を要求できます。各ケースに異なるコンフリクト解決方法を組み合わせて使用することで、驚くほど柔軟なシステムを実現できます。
利用可能なさまざまなコンフリクト解決策と組み合わせることで、分散システムには多くの選択肢が用意されますが、その実装は非常に複雑です。詳細には使用しませんが、利用可能なさまざまなオプションを認識するために、何が存在するかを知っておくことは重要だと思います。
現時点では、Erlangを使用した分散コンピューティングの基本に固執できます。
Erlangクラスタの設定
分散コンピューティングの誤謬を処理するという部分全体を除けば、分散Erlangで最も難しい部分は、まず最初に物事を正しく設定することです。異なるホスト間でノードを接続することは、特別な種類の苦痛です。これを避けるために、通常は単一コンピューター上の多くのノードを使用して試行しますが、これは物事を容易にする傾向があります。
前述のように、Erlangは各ノードに名前を付けて、それらを特定し、連絡できるようにします。名前はName@Hostという形式で、ホストはネットワーク上またはコンピューターのhostsファイル(OSX、Linux、その他のUnix系では/etc/hosts、ほとんどのWindowsインストールではC:\Windows\system32\drivers\etc\hosts)にある利用可能なDNSエントリに基づいています。すべての名前は、競合を避けるために一意である必要があります。同じホスト名で別のノードと同じ名前でノードを起動しようとすると、非常にひどいクラッシュメッセージが表示されます。
クラッシュを引き起こすためにこれらのシェルを起動する前に、名前について少し知っておく必要があります。名前には、短い名前と長い名前の2種類があります。長い名前は完全修飾ドメイン名(aaa.bbb.ccc)に基づいており、多くのDNSリゾルバーは、ピリオド(.)を含むドメイン名を完全修飾名と見なします。短い名前は、ピリオドのないホスト名に基づいており、ホストファイルまたは可能なDNSエントリを通じて解決されます。このため、短い名前を使用して単一コンピューター上に複数のErlangノードを設定する方が、長い名前を使用するよりも一般的に簡単です。最後に、名前は一意である必要があるため、短い名前のノードは長い名前のノードと通信できず、その逆もまた同様です。
長い名前と短い名前のどちらかを選択するには、2つの異なるオプションを使用してErlang VMを起動できます。erl -sname short_name@domainまたはerl -name long_name@some.domainです。名前だけでノードを起動することもできます。erl -sname short_nameまたはerl -name long_nameです。Erlangは、オペレーティングシステムの設定に基づいてホスト名を自動的に割り当てます。最後に、erl -name name@127.0.0.1のような名前でノードを起動して、直接IPアドレスを指定することもできます。
注:Windowsユーザーは、erlの代わりにwerlを使用する必要があります。ただし、分散ノードを起動して名前を付けるには、ショートカットまたは実行可能ファイルをクリックするのではなく、コマンドラインからノードを起動する必要があります。
2つのノードを起動しましょう
erl -sname ketchup ... (ketchup@ferdmbp)1>
erl -sname fries ... (fries@ferdmbp)1>
フライとケチャップを接続して(おいしいクラスタを作成するには)、最初のシェルに移動して次の関数を入力します。
(ketchup@ferdmbp)1> net_kernel:connect_node(fries@ferdmbp). true
net_kernel:connect_node(NodeName)関数は、別のErlangノードとの接続を設定します(いくつかのチュートリアルではnet_adm:ping(Node)を使用していますが、net_kernel:connect_node/1の方が真剣で信頼性があると思います!)。関数の呼び出しの結果としてtrueが表示された場合、おめでとうございます。分散Erlangモードになりました。falseが表示された場合は、ネットワークを正常に動作させるために苦労することになります。非常に迅速な修正として、ホストファイルを編集して、必要なホストを受け入れるようにします。もう一度試して、機能するかどうかを確認してください。
BIF node()を呼び出すことで独自のノード名を確認し、BIF nodes()を呼び出すことで接続先を確認できます。
(ketchup@ferdmbp)2> node(). ketchup@ferdmbp (ketchup@ferdmbp)3> nodes(). [fries@ferdmbp]
ノードを相互に通信させるために、非常に簡単なトリックを試してみましょう。各シェルのプロセスをローカルでshellとして登録します。
(ketchup@ferdmbp)4> register(shell, self()). true
(fries@ferdmbp)1> register(shell, self()). true
その後、名前でプロセスを呼び出すことができます。方法は、{Name, Node}にメッセージを送信することです。両方のシェルで試してみましょう。
(ketchup@ferdmbp)5> {shell, fries@ferdmbp} ! {hello, from, self()}.
{hello,from,<0.52.0>}
(fries@ferdmbp)2> receive {hello, from, OtherShell} -> OtherShell ! <<"hey there!">> end.
<<"hey there!">>
したがって、メッセージは明らかに受信され、別のシェルに何かを送信すると、それが受信されます。
(ketchup@ferdmbp)6> flush(). Shell got <<"hey there!">> ok
ご覧のとおり、タプル、アトム、pid、バイナリを問題なく透過的に送信します。他のErlangデータ構造も問題ありません。以上です。分散Erlangの使い方を学びました!他にも便利なBIFがあります。erlang:monitor_node(NodeName, Bool)です。この関数は、Boolの値としてtrueを指定して呼び出すプロセスに、ノードが死んだ場合に{nodedown, NodeName}形式のメッセージを送信させます。
他のノードの存続期間をチェックすることに依存する特別なライブラリを作成していない限り、erlang:monitor_node/2を使用する必要はほとんどありません。その理由は、link/1やmonitor/2などの関数はノード間で引き続き機能するためです。
friesノードから次のように設定した場合
(fries@ferdmbp)3> process_flag(trap_exit, true). false (fries@ferdmbp)4> link(OtherShell). true (fries@ferdmbp)5> erlang:monitor(process, OtherShell). #Ref<0.0.0.132>
そしてketchupノードを強制終了すると、friesのシェルプロセスは'EXIT'と監視メッセージを受信するはずです。
(fries@ferdmbp)6> flush().
Shell got {'DOWN',#Ref<0.0.0.132>,process,<6349.52.0>,noconnection}
Shell got {'EXIT',<6349.52.0>,noconnection}
ok
そして、それが表示される種類のものです。しかし、ちょっと待って。なぜpidはそんな風に見えるのでしょうか?正しく見ているのでしょうか?
(fries@ferdmbp)7> OtherShell. <6349.52.0>
何?これは<0.52.0>であるべきではありませんか?いいえ。ご覧のとおり、pidの表示方法は、プロセス識別子が実際にはどのようなものかの視覚的な表現にすぎません。最初の数値はノードを表し(0はプロセスが現在のノードから来ていることを意味します)、2番目はカウンター、3番目は、非常に多くのプロセスが作成され、最初のカウンターでは不十分な場合の2番目のカウンターです。pidの真の基礎となる表現は、次のようなものです。
(fries@ferdmbp)8> term_to_binary(OtherShell). <<131,103,100,0,15,107,101,116,99,104,117,112,64,102,101, 114,100,109,98,112,0,0,0,52,0,0,0,0,3>>
バイナリシーケンス<<107,101,116,99,104,117,112,64,102,101,114,100,109,98,112>>は実際には、プロセスが配置されているノードの名前である<<"ketchup@ferdmbp">>のlatin-1(またはASCII)表現です。次に、2つのカウンター<<0,0,0,52>>と<<0,0,0,0>>があります。最後の値(3)は、pidが古いノードから、死んだノードからなど、どこから来たのかを区別するためのトークン値です。そのため、pidはどこでも透過的に使用できます。
注:ノードを切断するためにノードを強制終了する代わりに、BIF erlang:disconnect_node(Node)を使用して、シャットダウンせずにノードを削除することもできます。
注:Pidの送信元ノードが不明な場合は、バイナリに変換してノード名を読み取る必要はありません。node(Pid)を呼び出すだけで、実行されているノードが文字列として返されます。
その他、使用できる興味深いBIFには、spawn/2、spawn/4、spawn_link/2、spawn_link/4があります。これらは他のspawn BIFとまったく同じように機能しますが、これらを使用すると、リモートノードで関数を生成できます。ケチャップノードからこれを実行してみてください。
(ketchup@ferdmbp)6> spawn(fries@ferdmbp, fun() -> io:format("I'm on ~p~n", [node()]) end).
I'm on fries@ferdmbp
<6448.50.0>
これは基本的にリモートプロシージャコールです。これ以上の苦労をすることなく、他のノードで任意のコードを実行することを選択できます!興味深いことに、関数は他のノードで実行されていますが、出力はローカルで受信します。そうです、出力でさえネットワークを介して透過的にリダイレクトできます。これは、グループリーダーの考えに基づいています。グループリーダーは、ローカルであるかどうかにかかわらず、同じように継承されます。
これらは、分散コードを作成するためにErlangで必要なすべてのツールです。あなたはマチェーテ、懐中電灯、口ひげを受け取りました。このような分散レイヤーなしでは、他の言語で達成するには非常に長い時間がかかるレベルにあります。今こそモンスターを倒す時です。それとも、まずクッキーモンスターについて学ぶ必要があるかもしれません。
クッキー

章の冒頭で、すべてのErlangノードはメッシュとして設定されているという考えについて述べました。誰かがノードに接続すると、他のすべてのノードに接続されます。同じハードウェア上で異なるErlangノードクラスタを実行したい場合があります。これらの場合、2つのErlangノードクラスタを誤って相互に接続したくありません。
そのため、Erlangの設計者はクッキーと呼ばれる小さなトークン値を追加しました。公式のErlangドキュメントなどのドキュメントでは、クッキーはセキュリティのトピックの下に記載されていますが、実際にはセキュリティではありません。もしそうなら、それは冗談として見られるべきです。なぜなら、誰もクッキーを安全なものと考えているとは真剣には考えられないからです。なぜですか?それは単純に、クッキーはノード間で共有する必要がある小さな一意の値であり、それらを相互に接続できるようにするためです。それらはパスワードよりもユーザー名という考えに近いものであり、誰もユーザー名(そしてそれ以外何もない)をセキュリティ機能と考えているとは考えていません。クッキーは、認証メカニズムではなく、ノードのクラスタを分割するために使用されるメカニズムとして、はるかに理にかなっています。
ノードにCookieを与えるには、コマンドラインに-setcookie Cookie引数を追加してノードを起動するだけです。2つの新しいノードで再度試してみましょう。
$ erl -sname salad -setcookie 'myvoiceismypassword' ... (salad@ferdmbp)1>
$ erl -sname mustard -setcookie 'opensesame' ... (mustard@ferdmbp)1>
これで、両方のノードに異なるCookieが設定され、互いに通信できなくなります。
(salad@ferdmbp)1> net_kernel:connect_node(mustard@ferdmbp). false
これは拒否されました。説明はほとんどありません。しかし、マスタードノードを見てみましょう。
=ERROR REPORT==== 10-Dec-2011::13:39:27 === ** Connection attempt from disallowed node salad@ferdmbp **
良いですね。では、サラダとマスタードを本当に一緒にしたいとしたらどうでしょうか?必要なことを行うために、erlang:set_cookie/2というBIFがあります。erlang:set_cookie(OtherNode, Cookie)を呼び出すと、その他のノードに接続する場合のみ、そのCookieが使用されます。代わりにerlang:set_cookie(node(), Cookie)を使用すると、将来のすべての接続に対してノードの現在のCookieが変更されます。変更を確認するには、erlang:get_cookie()を使用します。
(salad@ferdmbp)2> erlang:get_cookie(). myvoiceismypassword (salad@ferdmbp)3> erlang:set_cookie(mustard@ferdmbp, opensesame). true (salad@ferdmbp)4> erlang:get_cookie(). myvoiceismypassword (salad@ferdmbp)5> net_kernel:connect_node(mustard@ferdmbp). true (salad@ferdmbp)6> erlang:set_cookie(node(), now_it_changes). true (salad@ferdmbp)7> erlang:get_cookie(). now_it_changes
素晴らしいですね。最後に確認するCookieメカニズムが1つあります。この章の以前の例を試した場合は、ホームディレクトリを確認してください。そこには、.erlang.cookieという名前のファイルがあるはずです。そのファイルを読み取ると、PMIYERCHJZNZGSRJPVRKのようなランダムな文字列が表示されます。特定のコマンドでCookieを指定せずに分散ノードを起動するたびに、ErlangはCookieを生成してそのファイルに格納します。そして、Cookieを指定せずにノードを再度起動するたびに、VMはホームディレクトリ内を確認し、ファイル内のものを使用します。
リモートシェル
Erlangで最初に学んだことの1つは、^G(CTRL + G)を使用して実行中のコードを中断する方法でした。そこで、分散シェルのメニューを見ました。
(salad@ferdmbp)1> User switch command --> h c [nn] - connect to job i [nn] - interrupt job k [nn] - kill job j - list all jobs s [shell] - start local shell r [node [shell]] - start remote shell q - quit erlang ? | h - this message
r [node [shell]]オプションが私たちが探しているものです。マスタードノードでジョブを開始するには、次のようにします。
--> r mustard@ferdmbp
--> j
1 {shell,start,[init]}
2* {mustard@ferdmbp,shell,start,[]}
--> c
Eshell V5.8.4 (abort with ^G)
(mustard@ferdmbp)1> node().
mustard@ferdmbp
これで完了です。ローカルシェルと同じようにリモートシェルを使用できるようになりました。古いバージョンのErlangでは、オートコンプリートなどが機能しなくなるなど、いくつかの違いがあります。この方法は、-noshellオプションで実行されているノードで何かを変更する必要がある場合に非常に役立ちます。-noshellノードに名前がある場合、それに接続して、モジュールのリロード、コードのデバッグなど、管理関連のタスクを実行できます。
もう一度^Gを使用すると、元のノードに戻ることができます。ただし、セッションを停止する際は注意が必要です。q()またはinit:stop()を呼び出すと、リモートノードが終了します!

非表示ノード
Erlangノードはnet_kernel:connect_node/1を呼び出すことで接続できますが、ノード間のほぼすべてのやり取りによって接続が確立されることに注意する必要があります。spawn/2を呼び出すか、外部Pidにメッセージを送信すると、自動的に接続が確立されます。
これは、適切なクラスタがあり、いくつかの変更を加えるために単一のノードに接続したい場合に非常に面倒になる可能性があります。管理ノードが突然クラスタに統合され、他のノードが新しい同僚にタスクを送信できると考えるような事態は避けたいでしょう。これを行うには、あまり使用されないerlang:send(Dest, Message, [noconnect])関数を使用できます。これは、接続を作成せずにメッセージを送信しますが、エラーが発生しやすいです。
代わりに、-hiddenフラグを使用してノードを設定することをお勧めします。マスタードノードとサラダノードがまだ実行されていると仮定します。マスタードノードのみに接続する3番目のノードであるolivesを起動します(Cookieが同じであることを確認してください!)。
$ erl -sname olives -hidden ... (olives@ferdmbp)1> net_kernel:connect_node(mustard@ferdmbp). true (olives@ferdmbp)2> nodes(). [] (olives@ferdmbp)3> nodes(hidden). [mustard@ferdmbp]
ありました!ノードはサラダに接続しませんでしたが、一見したところ、マスタードにも接続していませんでした。しかし、node(hidden)を呼び出すと、そこに接続があることがわかります!マスタードノードが何を見ているか見てみましょう。
(mustard@ferdmbp)1> nodes(). [salad@ferdmbp] (mustard@ferdmbp)2> nodes(hidden). [olives@ferdmbp] (mustard@ferdmbp)3> nodes(connected). [salad@ferdmbp,olives@ferdmbp]
同様のビューですが、今度はnodes(connected) BIFを追加して、そのタイプに関係なくすべての接続を表示します。サラダノードは、特に接続するように指示されない限り、オリーブへの接続を決して認識しません。nodes/1のもう1つの興味深い用途はnodes(known)を使用することです。これにより、現在のノードが以前に接続したすべてのノードが表示されます。
リモートシェル、Cookie、および非表示ノードを使用すると、分散Erlangシステムの管理が簡素化されます。
壁は火でできており、ゴーグルは役に立たない
分散Erlangでファイアウォールを通過したい場合(トンネルを使用しない場合)、Erlang通信のためにいくつかのポートを開く必要があるでしょう。そのためには、EPMDのデフォルトポートであるポート4369を開く必要があります。これは、エリクソンによってEPMD向けに正式に登録されているため、良いアイデアです。これは、使用する標準準拠のオペレーティングシステムでは、そのポートがEPMD用に空いており、準備ができていることを意味します。
次に、ノード間の接続のためにポートの範囲を開く必要があります。問題は、Erlangがノード間の接続にランダムなポート番号を割り当てることです。ただし、ポートを割り当てる範囲を指定できる2つの非表示のアプリケーション変数があります。2つの値は、kernelアプリケーションのinet_dist_listen_minとinet_dist_listen_maxです。
例として、erl -name left_4_distribudead -kernel inet_dist_listen_min 9100 -kernel inet_dist_listen_max 9115のようにErlangを起動して、Erlangノードに使用する16ポートの範囲を設定できます。または、次のようなports.config構成ファイルを使用することもできます。
[{kernel,[
{inet_dist_listen_min, 9100},
{inet_dist_listen_max, 9115}
]}].
そして、erl -name the_army_of_darknodes -config portsとしてErlangノードを起動します。変数は同じ方法で設定されます。
彼方からの呼び出し
これまでに見たすべてのBIFと概念に加えて、開発者が分散処理で作業するのに役立ついくつかのモジュールがあります。その最初のものは、ノードを接続するために使用したnet_kernelであり、前述のように、ノードの切断にも使用できます。
非分散ノードを分散ノードに変換できるなど、他の高度な機能も備えています。
erl
...
1> net_kernel:start([romero, shortnames]).
{ok,<0.43.0>}
(romero@ferdmbp)2>
ここで、shortnamesまたはlongnamesを使用して、-snameまたは-nameと同等のものを定義できます。さらに、ノードが大きなメッセージを送信し、ノード間のハートビート時間が長くなる可能性があることがわかっている場合は、3番目の引数をリストに渡すことができます。これにより、net_kernel:start([Name, Type, HeartbeatInMilliseconds])が得られます。デフォルトでは、ハートビート遅延は15秒、つまり15000ミリ秒に設定されています。4回のハートビート失敗後、リモートノードは死んでいると見なされます。ハートビート遅延に4を掛けたものをティック時間と呼びます。
このモジュールの他の関数には、ノードのティック時間を変更して切断を回避するnet_kernel:set_net_ticktime(S)(ここでSは秒単位であり、ティック時間であるため、ハートビート遅延の4倍でなければなりません!)と、分散を停止して通常のノードに戻るnet_kernel:stop()があります。
(romero@ferdmbp)2> net_kernel:set_net_ticktime(5). change_initiated (romero@ferdmbp)3> net_kernel:stop(). ok 4>
分散処理に役立つ次のモジュールはglobalです。グローバルモジュールは、新しい代替プロセスレジストリです。データは接続されているすべてのノードに自動的に広がり、そこでデータが複製され、ノードの障害が処理され、ノードが再びオンラインになったときのさまざまな競合解決戦略がサポートされます。
global:register_name(Name, Pid)を呼び出すことで名前を登録し、global:unregister_name(Name)で登録を解除します。何も指さずに名前の転送を行いたい場合は、global:re_register_name(Name, Pid)を呼び出すことができます。global:whereis_name(Name)を使用してプロセスのIDを見つけることができ、global:send(Name, Message)を呼び出すことでメッセージを送信できます。必要なものがすべて揃っています。特に素晴らしいのは、プロセスを登録するために使用する名前が任意の項であることです。
2つのノードが接続され、両方のノードに同じ名前を共有する2つの異なるプロセスがある場合、名前の競合が発生します。このような場合、globalはデフォルトで一方のプロセスをランダムにキルします。その動作をオーバーライドする方法があります。名前を登録または再登録する場合は、関数の3番目の引数を渡します。
5> Resolve = fun(_Name,Pid1,Pid2) ->
5> case process_info(Pid1, message_queue_len) > process_info(Pid2, message_queue_len) of
5> true -> Pid1;
5> false -> Pid2
5> end
5> end.
#Fun<erl_eval.18.59269574>
6> global:register_name({zombie, 12}, self(), Resolve).
yes
Resolve関数は、メールボックスに最も多くのメッセージがあるプロセスを選択して保持します(関数がpidを返すプロセスです)。または、両方のプロセスに連絡して、最も多くの加入者を持つプロセスを尋ねたり、最初に応答したプロセスのみを保持したりすることもできます。 Resolve関数がクラッシュするか、pid以外のものを返す場合、プロセス名は登録解除されます。便宜上、globalモジュールには既に3つの関数が定義されています。
fun global:random_exit_name/3は、プロセスをランダムにキルします。これはデフォルトオプションです。fun global:random_notify_name/3は、2つのプロセスのいずれかをランダムに選択して生き残らせ、{global_name_conflict, Name}を敗北したプロセスに送信します。fun global:notify_all_name/3は、両方のpidの登録を解除し、{global_name_conflict, Name, OtherPid}メッセージを両方のプロセスに送信して、問題を自分で解決し、再度登録できるようにします。

globalモジュールには、名前の競合とノードの停止を検出するのが非常に遅いと言われるという欠点があります。それ以外では優れたモジュールであり、ビヘイビアでもサポートされています。ローカル名({local, Name})を使用するすべてのgen_Something:start_link(...)呼び出しを{global, Name}を使用するように変更し、すべての呼び出しとキャスト(およびその同等物)をNameではなく{global, Name}を使用するように変更すると、分散されます。
リストの次のモジュールはrpcで、リモートプロシージャコールを表します。リモートノードでコマンドを実行できる関数と、並列操作を容易にするいくつかの関数が含まれています。これらをテストするには、2つの異なるノードを起動して接続してみましょう。今回は、これがどのように機能するかを理解していることを前提としているため、手順は示しません。2つのノードはcthuluとlovecraftになります。
最も基本的なrpc操作はrpc:call/4-5です。これにより、リモートノードで特定の操作を実行し、ローカルで結果を取得できます。
(cthulu@ferdmbp)1> rpc:call(lovecraft@ferdmbp, lists, sort, [[a,e,f,t,h,s,a]]).
[a,a,e,f,h,s,t]
(cthulu@ferdmbp)2> rpc:call(lovecraft@ferdmbp, timer, sleep, [10000], 500).
{badrpc,timeout}
このCthuluノードの呼び出しでわかるように、4つの引数を持つ関数はrpc:call(Node, Module, Function, Args)という形式になります。5番目の引数を追加すると、タイムアウトが設定されます。rpc呼び出しは、実行された関数によって返されたもの、または失敗した場合に{badrpc, Reason}を返します。
以前に分散コンピューティングまたは並列コンピューティングの概念を学んだことがある場合は、プロミスについて聞いたことがあるかもしれません。プロミスはリモートプロシージャコールに似ていますが、非同期です。rpcモジュールでは、これが可能です。
(cthulu@ferdmbp)3> Key = rpc:async_call(lovecraft@ferdmbp, erlang, node, []). <0.45.0> (cthulu@ferdmbp)4> rpc:yield(Key). lovecraft@ferdmbp
rpc:async_call/4関数の結果とrpc:yield(Res)関数を組み合わせることで、非同期リモートプロシージャコールを行い、後で結果を取得できます。これは、実行するRPCが結果を返すのに時間がかかることがわかっている場合に特に役立ちます。このような状況では、RPCを送信し、その間他の作業(他の呼び出し、データベースからのレコードの取得、お茶を飲むなど)を行い、他に何もすることがなくなったときに結果を待ちます。もちろん、必要であれば自分のノードでそのような呼び出しを行うことができます。
(cthulu@ferdmbp)5> MaxTime = rpc:async_call(node(), timer, sleep, [30000]). <0.48.0> (cthulu@ferdmbp)6> lists:sort([a,c,b]). [a,b,c] (cthulu@ferdmbp)7> rpc:yield(MaxTime). ... [long wait] ... ok
何らかの理由でyield/1関数をタイムアウト値で使用したい場合は、代わりにrpc:nb_yield(Key, Timeout)を使用します。結果をポーリングするには、rpc:nb_yield(Key)を使用します(これはrpc:nb_yield(Key,0)と同等です)。
(cthulu@ferdmbp)8> Key2 = rpc:async_call(node(), timer, sleep, [30000]).
<0.52.0>
(cthulu@ferdmbp)9> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)10> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)11> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)12> rpc:nb_yield(Key2, 1000).
timeout
(cthulu@ferdmbp)13> rpc:nb_yield(Key2, 100000).
... [long wait] ...
{value,ok}
結果が重要でない場合は、rpc:cast(Node, Mod, Fun, Args)を使用して、別のノードにコマンドを送信し、それを忘れることができます。
未来はあなたの手の中にあります!しかし、待ってください。複数のノードを同時に呼び出したい場合はどうでしょうか?小さなクラスタに3つのノードを追加しましょう:minion1、minion2、minion3。これらはクトゥルフのミニオンです。彼らに質問したい場合は、3つの異なる呼び出しを送信する必要があり、命令を与えたい場合は、3回キャストする必要があります。これは非常に悪く、非常に大規模な軍隊ではスケールしません。
コツは、それぞれ呼び出しとキャストのために2つのRPC関数rpc:multicall(Nodes, Mod, Fun, Args)(オプションのTimeout引数付き)とrpc:eval_everywhere(Nodes, Mod, Fun, Args)を使用することです。
(cthulu@ferdmbp)14> nodes().
[lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]
(cthulu@ferdmbp)15> rpc:multicall(nodes(), erlang, is_alive, []).
{[true,true,true,true],[]}
これにより、4つのノードすべてが稼働中であること(そして応答不能なノードがなかったこと)がわかります。タプルの左側が稼働中で、右側が稼働していません。はい、erlang:is_alive()は、それが実行されているノードが稼働中かどうかだけを返すため、少し奇妙に見えるかもしれません。しかし、分散環境では、「稼働中」とは「到達可能」という意味であり、「実行中」という意味ではないことを改めて思い出してください。次に、クトゥルフが自分の手下をあまり評価しておらず、殺す、あるいは自滅するように仕向けることを決めたとしましょう。これは命令なので、キャストされます。このため、ミニオンノードでinit:stop()を呼び出すeval_everywhere/4を使用します。
(cthulu@ferdmbp)16> rpc:eval_everywhere([minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], init, stop, []).
abcast
(cthulu@ferdmbp)17> rpc:multicall([lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], erlang, is_alive, []).
{[true],[minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]}
誰が稼働中かを確認すると、ラヴクラフトノードだけが残り、ミニオンたちは従順な生き物でした。RPCには他にも興味深い関数がいくつかありますが、ここでは主要な用途について説明しました。詳細を知りたい場合は、モジュールのドキュメントを参照することをお勧めします。
ディストリブノミコンの埋葬
さて、Erlang分散の基本の大部分は以上です。考慮すべき点が数多くあり、覚えておくべき属性もたくさんあります。分散アプリケーションを開発する必要があるときはいつでも、潜在的に遭遇する可能性のある分散コンピューティングの誤謬(もしあれば)を自問してください。顧客から、一貫性と可用性を維持しながらネットスプリットを処理するシステムを構築するよう依頼された場合、CAP定理を冷静に説明するか、逃げる(最大限の効果を得るために窓から飛び降りるなど)必要があります。
一般的に、1000個の独立したノードが通信したり、互いに依存したりすることなく作業できるアプリケーションは、最高のスケーラビリティを提供します。ノード間の依存関係が増えるほど、どのような分散レイヤーを使用しても、スケールするのが難しくなります。これはゾンビと同じです(本当に!)。ゾンビは、その数が非常に多く、集団として殺すのが不可能なほど難しいことから恐ろしいのです。個々のゾンビは非常に遅く、脅威とは程遠い場合がありますが、大群は、多くのゾンビメンバーを失ってもかなりの被害を与える可能性があります。人間の生存者グループは、知性を組み合わせて協力することで素晴らしいことを成し遂げることができますが、被る損失はそれぞれグループとその生存能力に大きな負担となります。
とは言え、始めるのに必要なツールは揃っています。次の章では、分散OTPアプリケーションの概念を紹介します。これは、ハードウェア障害に対する乗っ取りとフェールオーバーメカニズムを提供しますが、一般的な分散ではありません。むしろ、死んだゾンビを復活させるようなものです。