並行処理へのヒッチハイクガイド
21世紀の流行遅れの始まりの、未開拓な奥地には、人類の知識の小さなサブセットが存在します。
この人類の知識のサブセットの中には、フォン・ノイマン型アーキテクチャが非常に原始的で、RPN電卓がかなり素晴らしいアイデアだと考えられているような、全く重要ではない小さな分野があります。
この分野には、または、むしろかつて、問題がありました。それは、並列ソフトウェアを書こうとすると、ほとんどの人がかなりの時間不幸だったということです。この問題に対して多くの解決策が提案されましたが、それらのほとんどは、ロックやミューテックスなどと呼ばれる小さなロジックの断片の処理に大きく関わっていました。これは奇妙なことです。なぜなら、並列化が必要だったのは、小さなロジックの断片ではなかったからです。
そして、問題は残りました。多くの人々は意地悪で、そのほとんどは惨めでした。RPN電卓を持っている人でさえも。
多くの人が、プログラミング言語に並列処理を追加しようとしたのは大きな間違いであり、どのプログラムも最初のスレッドから離れるべきではなかったという意見を持つようになりました。
注意: 『銀河ヒッチハイクガイド』のパロディは楽しいです。まだ読んでいないなら読んでみてください。良いですよ!
慌てるな
こんにちは。今日(または、あなたがこれを読んでいるのが明日でも)、並行Erlangについてお話しします。おそらくあなたは以前に並行処理について読んだり、扱ったことがあるでしょう。 また、マルチコアプログラミングの出現について興味があるかもしれません。いずれにせよ、最近話題になっている並行処理の話がきっかけで、この本を読んでいる可能性が高いでしょう。
また、マルチコアプログラミングの出現について興味があるかもしれません。いずれにせよ、最近話題になっている並行処理の話がきっかけで、この本を読んでいる可能性が高いでしょう。
ただし、注意が必要です。この章はほとんどが理論です。頭痛がしたり、プログラミング言語の歴史にうんざりしたり、ただプログラムをしたいだけなら、章の終わりにスキップするか、次の章にスキップした方が良いかもしれません(そこではより実用的な知識が示されます)。
私はすでに本の序章で、Erlangの並行処理はメッセージパッシングとアクターモデルに基づいており、人々が手紙だけでコミュニケーションをとる例を挙げたと説明しました。後でまた詳しく説明しますが、まず第一に、並行性と並列性の違いを定義することが重要だと考えています。
多くの場所で、両方の単語は同じ概念を指します。Erlangの文脈では、しばしば2つの異なるアイデアとして使用されます。多くのErlangプログラマーにとって、並行性とは、多くのアクターが独立して実行されているが、必ずしもすべて同時に実行されているわけではないという考えを指します。並列性とは、アクターがまさに同時に実行されていることです。コンピュータサイエンスのさまざまな分野でこのような定義に合意があるようには見えませんが、このテキストではこのように使用します。他の情報源や人々が同じ用語を異なる意味で使用しても驚かないでください。
これは、Erlangは、80年代にすべてがシングルコアプロセッサで行われていたときから、最初から並行性を持っていたということです。各Erlangプロセスは、マルチコアシステムの前に行ったデスクトップアプリケーションのように、実行するために独自の時間のスライスを持っていました。
当時も並列処理は可能でした。必要なのは、コードを実行している2台目のコンピューターを用意し、最初のコンピューターと通信することだけでした。それでも、この設定では2つのアクターしか並列に実行できませんでした。今日では、マルチコアシステムにより、1台のコンピューターで並列処理が可能になり(一部の産業用チップには数十個のコアがあります)、Erlangはこの可能性を最大限に活用しています。
あまりにもコーラを飲みすぎないでください
並行性と並列性の区別は重要です。なぜなら、多くのプログラマーは、Erlangが実際にそうなる数年前からマルチコアコンピュータに対応していたという信念を持っているからです。Erlangは、2000年代半ばに真の対称型マルチプロセッシングに適合し、2009年の言語のR13Bリリースで実装のほとんどを正しく行いました。それまでは、SMPパフォーマンスの低下を避けるために無効にする必要がありました。SMPなしでマルチコアコンピュータで並列処理を行うには、代わりにVMの多くのインスタンスを起動します。
興味深い事実は、Erlangの並行処理がすべて分離されたプロセスに関するものであるため、言語レベルで真の並列処理を言語にもたらすために概念的な変更は必要なかったということです。すべての変更は、プログラマーの目から離れたVMで透過的に行われました。
並行性の概念

当時、Erlangの言語としての開発は非常に迅速で、Erlang自体で電話交換機に取り組むエンジニアからの頻繁なフィードバックがありました。これらの相互作用により、プロセスベースの並行処理と非同期メッセージパッシングが、彼らが直面した問題をモデル化するのに適した方法であることが証明されました。さらに、電話の世界では、Erlangが登場する前から、並行処理に向かう特定の文化がすでにありました。これは、エリクソンで以前に作成された言語であるPLEXと、それを使用して開発された交換機であるAXEから受け継がれたものです。Erlangはこの傾向に従い、利用可能な以前のツールを改善しようとしました。
Erlangは、優れたものと見なされる前に満たす必要のあるいくつかの要件がありました。主なものは、多数のスイッチにまたがって数千人のユーザーをスケールアップしてサポートし、次に、コードを停止させないほど高い信頼性を達成することでした。
スケーラビリティ
まずスケーリングに焦点を当てます。スケーラビリティを実現するために必要な性質がいくつかありました。ユーザーは、特定のイベント(つまり、電話を受ける、電話を切るなど)にのみ反応するプロセスとして表されるため、理想的なシステムは、小さな計算を実行し、イベントが発生するたびに非常に迅速にそれらを切り替えるプロセスをサポートします。効率を高めるために、プロセスが非常に迅速に開始され、非常に迅速に破棄され、本当に高速に切り替えられるようにすることが理にかなっていました。これらを達成するには、軽量であることが必須でした。また、プロセスプール(作業を分割する固定量のプロセス)のようなものを使用しないためにも必須でした。代わりに、必要なだけ多くのプロセスを使用できるプログラムを設計する方がはるかに簡単です。
スケーラビリティのもう1つの重要な側面は、ハードウェアの制限を回避できるようにすることです。これを行うには2つの方法があります。ハードウェアを改善するか、ハードウェアを追加するかです。最初のオプションは、ある程度のところまでは有用ですが、それを過ぎると非常に高価になります(つまり、スーパーコンピュータを購入するなど)。2番目のオプションは通常安価であり、ジョブを実行するためにより多くのコンピューターを追加する必要があります。これは、言語の一部としてディストリビューションが役立つ可能性がある場所です。
とにかく、小さなプロセスに戻りますが、電話アプリケーションには高い信頼性が必要なため、最もクリーンな方法は、プロセスがメモリを共有することを禁止することであると決定されました。共有メモリは、(特に異なるノード間で共有されるデータで)クラッシュ後に不安定な状態になる可能性があり、いくつかの複雑さがありました。代わりに、プロセスはすべてのデータがコピーされるメッセージを送信することによって通信する必要があります。これは遅くなるリスクがありますが、より安全です。
フォールトトレランス
これにより、Erlangの2番目のタイプの要件、つまり信頼性が導き出されます。Erlangの最初のライターは常に、失敗が一般的であることを念頭に置いていました。バグを防ごうといくら頑張っても、ほとんどの場合、いくつかのバグは発生します。バグが発生しない場合でも、ハードウェアの故障を常に止めることはできません。したがって、すべてのエラーを防ごうとするのではなく、エラーや問題を処理する良い方法を見つけることが重要です。
メッセージパッシングを使用した複数のプロセスという設計アプローチを採用することは良いアイデアであることがわかりました。エラー処理を比較的簡単に追加できるからです。軽量プロセス(迅速な再起動とシャットダウンのために作成)を例にとってみましょう。いくつかの調査では、大規模なソフトウェアシステムにおけるダウンタイムの主な原因は、断続的または一時的なバグであると証明されています(ソース)。次に、データを破損させるエラーは、エラーと不正なデータがシステムの残りの部分に伝播するのを防ぐために、システムの障害のある部分を可能な限り迅速に死なせる必要があるという原則があります。ここでのもう1つの概念は、システムが終了する方法は多数存在し、そのうちの2つはクリーンシャットダウンとクラッシュ(予期しないエラーで終了)であるということです。
ここでは、最悪のケースは明らかにクラッシュです。安全な解決策は、すべてのクラッシュがクリーンシャットダウンと同じであることを確認することです。これは、共有なしやシングルアサインメント(プロセスのメモリを分離する)などの慣行を通じて行うことができます。また、ロック(クラッシュ時にロックが解除されない可能性があり、他のプロセスがデータにアクセスしたり、データが矛盾した状態のままになるのを防ぐ)など、さらに詳しく説明しない他の事柄もErlangの設計の一部でした。Erlangでの理想的な解決策は、データ破損と一時的なバグを回避するために、できるだけ早くプロセスを終了することです。軽量プロセスは、この点で重要な要素です。さらに、エラー処理メカニズムも言語の一部であり、プロセスが他のプロセスを監視できるようにします(これは、エラーとプロセスの章で説明されています)。プロセスがいつ死んだかを知り、それに対して何をするかを決定するために。
プロセスを非常に迅速に再起動すればクラッシュに対処できると仮定すると、次に発生する問題はハードウェアの故障です。誰かが実行中のコンピューターを蹴ったときに、プログラムが実行され続けるようにするにはどうすればよいでしょうか? レーザー検出と戦略的に配置されたサボテンで構成された派手な防御メカニズムはしばらくの間は機能するかもしれませんが、永遠には続きません。ヒントは、プログラムを一度に複数のコンピューターで実行することです。これは、いずれにせよスケーリングに必要でした。これは、メッセージパッシング以外の通信チャネルを持たない独立したプロセスのもう1つの利点です。ローカルであろうと別のコンピューターであろうと、同じ方法で動作させることができ、ディストリビューションによるフォールトトレランスをプログラマーに対してほぼ透過的にすることができます。
レーザー検出と戦略的に配置されたサボテンで構成された派手な防御メカニズムはしばらくの間は機能するかもしれませんが、永遠には続きません。ヒントは、プログラムを一度に複数のコンピューターで実行することです。これは、いずれにせよスケーリングに必要でした。これは、メッセージパッシング以外の通信チャネルを持たない独立したプロセスのもう1つの利点です。ローカルであろうと別のコンピューターであろうと、同じ方法で動作させることができ、ディストリビューションによるフォールトトレランスをプログラマーに対してほぼ透過的にすることができます。
分散型であることは、プロセス間がどのように通信できるかに直接的な影響を与えます。分散化における最大のハードルの1つは、関数を呼び出したときにノード(リモートコンピュータ)が存在していたからといって、呼び出しの全送信中にそのノードが存在し続ける、あるいは正しく実行されると仮定できないことです。誰かがケーブルにつまずいたり、マシンのプラグを抜いたりすると、アプリケーションがハングしてしまうでしょう。あるいは、クラッシュするかもしれません。誰にも分かりません。
さて、非同期メッセージパッシングの選択もまた、良い設計上の選択だったことが分かりました。非同期メッセージを使用したプロセスモデルでは、メッセージは1つのプロセスから2番目のプロセスに送信され、読み取られるまで受信側プロセスの内部のメールボックスに格納されます。メッセージは、受信側プロセスが存在するかどうかを確認せずに送信されることに言及することが重要です。なぜなら、そうすることは役に立たないからです。前の段落で示唆されているように、メッセージが送信されてから受信されるまでの間にプロセスがクラッシュするかどうかを知ることは不可能です。そして、受信されたとしても、それが実行されるかどうか、あるいは受信側プロセスがその前に死んでしまうかどうかも知ることはできません。非同期メッセージは、何が起こるかについての前提がないため、安全なリモート関数呼び出しを可能にします。プログラマーが知るべきです。配信の確認が必要な場合は、元のプロセスへの返信として2番目のメッセージを送信する必要があります。このメッセージは同じ安全なセマンティクスを持ち、この原則に基づいて構築するプログラムやライブラリも同様です。
実装
さて、Erlangでは軽量プロセスと非同期メッセージパッシングを採用することが決定しました。これをどのように機能させるのでしょうか?まず第一に、オペレーティングシステムがプロセスの処理を信頼することはできません。オペレーティングシステムは、プロセスを処理するためにさまざまな方法を持っており、そのパフォーマンスは大きく異なります。ほとんどすべてが、標準的なErlangアプリケーションに必要なものに対して遅すぎるか、重すぎます。これをVMで行うことで、Erlangの実装者は最適化と信頼性を制御できます。今日、Erlangのプロセスは約300ワードのメモリを消費し、マイクロ秒単位で作成できます。これは、最近の主要なオペレーティングシステムでは不可能なことです。
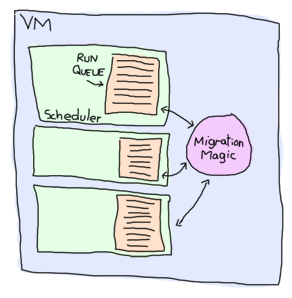
プログラムが作成する可能性のあるこれらすべてのプロセスを処理するために、VMはコアごとに1つのスレッドをスケジューラとして起動します。これらのスケジューラはそれぞれ、時間を費やすErlangプロセスのリストである実行キューを持っています。いずれかのスケジューラの実行キューにタスクが多すぎる場合、一部のタスクは別のスケジューラに移行されます。つまり、各Erlang VMはすべての負荷分散を処理し、プログラマーはそれについて心配する必要はありません。負荷を調整および分散するために、過負荷のプロセスでメッセージを送信できる速度を制限するなど、他の最適化も行われます。
すべての難しいことはそこにあり、あなたのために管理されています。それがErlangで並列処理を容易にする理由です。並列処理を行うということは、2番目のコアを追加するとプログラムの速度が2倍になり、4つ追加すると4倍になるなど、そうなるはずですよね?それは場合によります。このような現象は、コアまたはプロセッサの数に対する速度向上に関して線形スケーリングと呼ばれています(下のグラフを参照)。現実の世界では、無料のランチのようなものはありません(そうですね、葬儀ではありますが、それでも誰かがどこかで支払う必要があります)。
完全に線形スケーリングではない
線形スケーリングを実現することの難しさは、言語自体によるものではなく、解決すべき問題の性質によるものです。非常にうまくスケールする問題は、非常に並列であると言われることがよくあります。インターネットで非常に並列な問題を検索すると、レイトレーシング(3D画像を作成する方法)、暗号化におけるブルートフォース検索、天気予報などの例が見つかるでしょう。
時々、人々はIRCチャンネル、フォーラム、メーリングリストに現れて、Erlangがそのような問題を解決するために使用できるか、またはGPUでプログラミングするために使用できるかどうかを尋ねます。答えはほとんどの場合「いいえ」です。理由は比較的簡単です。これらの問題はすべて、通常、大量のデータ処理を伴う数値アルゴリズムに関するものです。Erlangはこれが得意ではありません。
Erlangの非常に並列な問題は、より高いレベルに存在します。通常、チャットサーバー、電話交換機、Webサーバー、メッセージキュー、Webクローラー、または実行される作業を独立した論理エンティティ(アクター)として表現できるその他のアプリケーションなどの概念に関係しています。この種の問題は、ほぼ線形のスケーリングで効率的に解決できます。
多くの問題では、このようなスケーリング特性は決して示されません。実際、それをすべて失うために、1つの中央化された一連の操作が必要なだけです。並列プログラムの速度は、最も遅い逐次部分の速度にすぎません。その現象の例は、ショッピングモールに行くたびに観察できます。何百人もの人々が同時に買い物をすることができ、互いに干渉することはめったにありません。その後、支払いの時間になると、レジ係の数が帰る準備ができている顧客の数よりも少ないとすぐに、行列ができます。
顧客ごとに1つのレジ係を追加することは可能ですが、そうすると、すべての顧客が一度にモールに出入りできないため、顧客ごとにドアが必要になります。
言い換えれば、顧客はそれぞれの品物を並行して選び、一人でも店に千人いても買い物をするのに同じくらいの時間がかかる可能性がありますが、それでも支払いをするのを待つ必要があります。したがって、彼らの買い物体験は、彼らが列で待って支払うのにかかる時間よりも短くなることは決してありません。
この原則の一般化は、アムダールの法則と呼ばれています。これは、並列処理を追加するたびに、システムでどれくらいの速度向上を期待できるか、またその割合を示します。

アムダールの法則によると、50%並列のコードは、以前の2倍よりも速くなることはなく、95%並列のコードは、十分なプロセッサを追加すると、理論的には約20倍速くなると予想できます。このグラフで興味深いのは、プログラムの最後のいくつかの逐次部分を取り除くことで、最初はそれほど並列ではないプログラムで逐次コードを可能な限り削除することと比較して、比較的大きな理論上の速度向上が可能になることです。
あまりにもコーラを飲みすぎないでください
並列処理はすべての問題に対する答えではありません。場合によっては、並列処理を行うと、アプリケーションの速度が低下することさえあります。これは、プログラムが100%逐次であるにもかかわらず、複数のプロセスを使用している場合に発生する可能性があります。
この最良の例の1つは、リングベンチマークです。リングベンチマークは、何千ものプロセスがデータを円を描くように次々と渡していくテストです。必要であれば、電話ゲームを考えてみてください。このベンチマークでは、一度に1つのプロセスだけが有用な処理を行いますが、Erlang VMはそれでもコア間で負荷を分散し、すべてのプロセスに時間の割り当てを与えるのに時間を費やします。
これは、多くの一般的なハードウェア最適化に反し、VMは無駄な処理に時間を費やすことになります。これにより、純粋に逐次的なアプリケーションは、多くの場合、単一のコアよりも多くのコアで大幅に遅く実行されます。この場合、対称型マルチプロセッシング($ erl -smp disable)を無効にすることが良い考えかもしれません。
さようなら、そしてすべての魚に感謝を!
もちろん、この章は、Erlangでの並行処理に必要な3つのプリミティブ、つまり新しいプロセスの生成、メッセージの送信、およびメッセージの受信を示さなければ完了しません。実際には、本当に信頼性の高いアプリケーションを作成するためにさらに多くのメカニズムが必要ですが、今のところこれで十分でしょう。
私は問題を全体的にスキップしており、プロセスが実際に何であるかをまだ説明していません。実際、それは関数に過ぎません。それだけです。関数を実行し、完了すると消えます。技術的には、プロセスには(メッセージ用のメールボックスなどの)隠された状態もありますが、今のところ関数で十分です。
新しいプロセスを開始するために、Erlangは単一の関数を受け取って実行する関数spawn/1を提供します。
1> F = fun() -> 2 + 2 end. #Fun<erl_eval.20.67289768> 2> spawn(F). <0.44.0>
spawn/1(<0.44.0>)の結果は、プロセス識別子と呼ばれ、コミュニティでは単にPID、Pid、またはpidと書かれることがよくあります。プロセス識別子は、VMのライフサイクルのある時点で存在(または存在した可能性のある)するプロセスを表す任意の値です。これは、プロセスと通信するためのアドレスとして使用されます。
関数Fの結果を確認できないことに気付くでしょう。そのpidしか取得できません。それは、プロセスが何も返さないからです。
では、どうすればFの結果を見ることができるのでしょうか?さて、2つの方法があります。最も簡単な方法は、取得したものを出力することです。
3> spawn(fun() -> io:format("~p~n",[2 + 2]) end).
4
<0.46.0>
これは実際のプログラムには実用的ではありませんが、Erlangがどのようにプロセスをディスパッチするかを確認するのに役立ちます。幸いなことに、io:format/2を使用すれば実験するのに十分です。関数timer:sleep/1を使用して、10個のプロセスをすばやく開始し、それぞれをしばらく一時停止します。この関数は整数値Nを受け取り、Nミリ秒待機してからコードを再開します。遅延後、プロセスに存在する値が出力されます。
4> G = fun(X) -> timer:sleep(10), io:format("~p~n", [X]) end.
#Fun<erl_eval.6.13229925>
5> [spawn(fun() -> G(X) end) || X <- lists:seq(1,10)].
[<0.273.0>,<0.274.0>,<0.275.0>,<0.276.0>,<0.277.0>,
<0.278.0>,<0.279.0>,<0.280.0>,<0.281.0>,<0.282.0>]
2
1
4
3
5
8
7
6
10
9
順序が意味を成していません。並列処理へようこそ。プロセスは同時に実行されているため、イベントの順序は保証されなくなりました。これは、Erlang VMがプロセスを実行するタイミングを決定するために多くのトリックを使用し、それぞれが十分な時間を確保するようにしているためです。多くのErlangサービスは、入力しているシェルを含むプロセスとして実装されています。プロセスは、システム自体が必要とするものとバランスをとる必要があり、これが奇妙な順序の原因である可能性があります。
注:対称型マルチプロセッシングが有効かどうかにかかわらず、結果は似ています。それを証明するために、$ erl -smp disableを使用してErlang VMを起動するだけでテストできます。
そもそもErlang VMがSMPサポートありで実行されているか、なしで実行されているかを確認するには、オプションなしで新しいVMを起動し、最初の行の出力を探します。[smp:2:2] [rq:2]というテキストが表示されたら、SMPが有効になっており、2つのコアで2つの実行キュー(rq、またはスケジューラ)が実行されていることを意味します。[rq:1]しか表示されない場合は、SMPが無効になっている状態で実行されていることを意味します。
参考までに、[smp:2:2]は、2つのスケジューラを備えた2つのコアが利用可能であることを意味します。[rq:2]は、2つの実行キューがアクティブであることを意味します。以前のバージョンのErlangでは、複数のスケジューラを持つことができましたが、共有の実行キューは1つだけでした。R13B以降では、デフォルトでスケジューラごとに1つの実行キューがあります。これにより、並列処理が向上します。
シェル自体が通常のプロセスとして実装されていることを証明するために、現在のプロセスのpidを返すBIFself/0を使用します。
6> self(). <0.41.0> 7> exit(self()). ** exception exit: <0.41.0> 8> self(). <0.285.0>
そして、プロセスが再起動されるため、pidが変更されます。これがどのように機能するかの詳細は後で説明します。今のところ、カバーすべき基本的なことがまだあります。今最も重要なことは、メッセージをやり取りする方法を理解することです。なぜなら、誰もプロセスの結果の値を常にアウトプットし、それを他のプロセスに手動で入力するという状況に陥りたくないからです(少なくとも私はそうしたくありません)。
メッセージパッシングに必要な次のプリミティブは、演算子!、別名bang記号です。左辺にはpidを取り、右辺には任意のErlangタームを取ります。すると、タームはpidによって表されるプロセスに送信され、そこでアクセスできます。
9> self() ! hello. hello
メッセージはプロセスのメールボックスに入れられましたが、まだ読み込まれていません。ここで示されている2番目のhelloは、送信操作の戻り値です。つまり、次のようにすることで、同じメッセージを多くのプロセスに送信できます。
10> self() ! self() ! double. double
これは、self() ! (self() ! double)と同等です。プロセスのメールボックスについて注意すべき点は、メッセージが受信された順序で保持されるということです。メッセージが読み込まれるたびに、メールボックスから取り出されます。これも、手紙を書く人々の例を用いた入門編と少し似ています。

現在のメールボックスの内容を確認するには、シェルでflush()コマンドを使用できます。
11> flush(). Shell got hello Shell got double Shell got double ok
この関数は、受信したメッセージを出力するショートカットにすぎません。つまり、プロセスの結果を変数にバインドすることはまだできませんが、少なくとも、プロセス間でメッセージを送信し、それが受信されたかどうかを確認する方法はわかりました。
誰も読まないメッセージを送信することは、エモい詩を書くことと同じくらい役に立ちません。だからこそ、receive文が必要なのです。シェルで長時間遊ぶのではなく、イルカについての短いプログラムを作成して、それについて学びましょう。
-module(dolphins).
-compile(export_all).
dolphin1() ->
receive
do_a_flip ->
io:format("How about no?~n");
fish ->
io:format("So long and thanks for all the fish!~n");
_ ->
io:format("Heh, we're smarter than you humans.~n")
end.
ご覧のとおり、receiveは構文的にはcase ... ofに似ています。実際、パターンは、caseとofの間の式ではなく、メッセージからの変数をバインドすることを除いて、まったく同じように機能します。receiveにはガードも設定できます。
receive
Pattern1 when Guard1 -> Expr1;
Pattern2 when Guard2 -> Expr2;
Pattern3 -> Expr3
end
これで、上記のモジュールをコンパイルし、実行して、イルカとの通信を開始できます。
11> c(dolphins).
{ok,dolphins}
12> Dolphin = spawn(dolphins, dolphin1, []).
<0.40.0>
13> Dolphin ! "oh, hello dolphin!".
Heh, we're smarter than you humans.
"oh, hello dolphin!"
14> Dolphin ! fish.
fish
15>
ここでは、spawn/3を使用した新しいスポーン方法を紹介します。単一の関数を取るのではなく、spawn/3は、モジュール、関数、およびその引数を独自の引数として取ります。関数が実行されると、次のイベントが発生します。
- 関数が
receive文に到達します。プロセスのメールボックスが空であるため、イルカはメッセージを受け取るまで待機します。 - メッセージ"oh, hello dolphin!"が受信されます。関数は
do_a_flipとのパターンマッチを試みます。これは失敗するため、パターンfishが試行され、これも失敗します。最後に、メッセージは包括的な句(_)に一致します。 - プロセスはメッセージ"Heh, we're smarter than you humans."を出力します。
次に、最初に送信したメッセージが機能した場合、2番目のメッセージはプロセス<0.40.0>からまったく反応を引き起こさなかったことに注意する必要があります。これは、関数が"Heh, we're smarter than you humans."を出力すると、関数が終了し、プロセスも終了したためです。イルカを再起動する必要があります。
8> f(Dolphin). ok 9> Dolphin = spawn(dolphins, dolphin1, []). <0.53.0> 10> Dolphin ! fish. So long and thanks for all the fish! fish
そして、今回はfishメッセージが機能します。io:format/2を使用するのではなく、イルカからの返信を受信できると便利ではないでしょうか。もちろん便利でしょう(なぜ私は聞いているのでしょうか?)。この章の前半で、プロセスがメッセージを受信したかどうかを知る唯一の方法は、返信を送信することであると述べました。イルカのプロセスは、誰に返信するのかを知る必要があります。これは、郵便サービスと同じように機能します。誰かに手紙に返事をしてもらいたい場合は、住所を追加する必要があります。Erlangの用語では、これはプロセスのpidをタプルにパッケージ化することで行われます。最終的な結果は、{Pid, Message}のようなメッセージです。このようなメッセージを受け入れる新しいイルカ関数を作成しましょう。
dolphin2() ->
receive
{From, do_a_flip} ->
From ! "How about no?";
{From, fish} ->
From ! "So long and thanks for all the fish!";
_ ->
io:format("Heh, we're smarter than you humans.~n")
end.
ご覧のとおり、メッセージとしてdo_a_flipとfishを受け入れるのではなく、変数Fromが必要になりました。ここにプロセス識別子が入ります。
11> c(dolphins).
{ok,dolphins}
12> Dolphin2 = spawn(dolphins, dolphin2, []).
<0.65.0>
13> Dolphin2 ! {self(), do_a_flip}.
{<0.32.0>,do_a_flip}
14> flush().
Shell got "How about no?"
ok
かなりうまく機能しているようです。送信したメッセージへの返信を受け取ることができます(各メッセージにアドレスを追加する必要があります)が、呼び出しごとに新しいプロセスを開始する必要があります。再帰はこの問題を解決する方法です。関数が終わらず、常にメッセージを待つように、関数自体を呼び出すだけです。これが実践的な関数dolphin3/0です。
dolphin3() ->
receive
{From, do_a_flip} ->
From ! "How about no?",
dolphin3();
{From, fish} ->
From ! "So long and thanks for all the fish!";
_ ->
io:format("Heh, we're smarter than you humans.~n"),
dolphin3()
end.
ここでは、包括的な句とdo_a_flip句の両方が、dolphin3/0の助けを借りてループします。関数が末尾再帰であるため、スタックをオーバーフローしないことに注意してください。これらのメッセージのみが送信される限り、イルカのプロセスは無期限にループします。ただし、fishメッセージを送信すると、プロセスは停止します。
15> Dolphin3 = spawn(dolphins, dolphin3, []).
<0.75.0>
16> Dolphin3 ! Dolphin3 ! {self(), do_a_flip}.
{<0.32.0>,do_a_flip}
17> flush().
Shell got "How about no?"
Shell got "How about no?"
ok
18> Dolphin3 ! {self(), unknown_message}.
Heh, we're smarter than you humans.
{<0.32.0>,unknown_message}
19> Dolphin3 ! Dolphin3 ! {self(), fish}.
{<0.32.0>,fish}
20> flush().
Shell got "So long and thanks for all the fish!"
ok
これで、dolphins.erlは終わりです。ご覧のとおり、メッセージごとに1回返信し、その後も継続するという期待される動作を尊重しています。ただし、fish呼び出しは除きます。イルカは私たちのクレイジーな人間の滑稽さにうんざりして、私たちを永久に去りました。

これで終わりです。これがErlangの同時実行性のすべての核心です。プロセスと基本的なメッセージパッシングを見てきました。本当に役に立つ信頼性の高いプログラムを作成するためには、さらに多くの概念を理解する必要があります。それらのいくつかを次の章で、さらにその後の章で見ていきます。