アプリケーションの数
OTP アプリケーションから実際のアプリケーションへ
私たちの ppool アプリは有効な OTP アプリケーションになり、これが何を意味するのか理解できるようになりました。しかし、プロセスプールを実際に使用して何か役に立つものを構築できると良いでしょう。アプリケーションの知識をさらに深めるために、2 番目のアプリケーションを作成します。これは `ppool` に依存しますが、「nagger」よりも自動化の恩恵を受けることができます。
`erlcount` と名付けるこのアプリケーションの目的は比較的単純です。あるディレクトリを再帰的に調べ、すべての Erlang ファイル(`.erl` で終わる)を見つけ、正規表現を実行して、モジュール内の指定された文字列のすべてのインスタンスをカウントします。結果は集計されて最終結果が得られ、画面に出力されます。
この特定のアプリケーションは比較的単純で、プロセスプールに大きく依存します。構造は次のとおりです。
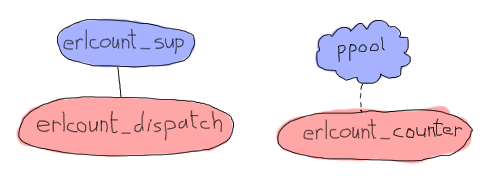
上の図では、`ppool` はアプリケーション全体を表していますが、`erlcount_counter` がプロセスプールのワーカーになることを示すことのみを意味します。これはファイルを開き、正規表現を実行して、カウントを返します。プロセス/モジュール `erlcount_sup` はスーパーバイザーになり、`erlcount_dispatch` はディレクトリの参照、`ppool` にワーカーのスケジュールを要求し、結果をコンパイルする役割を担う単一のサーバーになります。また、ディレクトリの読み取り、データのコンパイルなどのすべての関数をホストする役割を担う `erlcount_lib` モジュールを追加し、他のモジュールにはこれらの呼び出しを調整する役割を担わせます。最後は、アプリケーションコールバックモジュールであるという唯一の目的を持つ `erlcount` モジュールです。
最初の手順は、前回のアプリと同様に、必要なディレクトリ構造を作成することです。必要に応じて、ファイルスタブをいくつか追加することもできます。
ebin/ - erlcount.app include/ priv/ src/ - erlcount.erl - erlcount_counter.erl - erlcount_dispatch.erl - erlcount_lib.erl - erlcount_sup.erl test/ Emakefile
以前のものとそれほど変わりはありません。以前使用した Emakefile をコピーすることもできます。
アプリケーションのほとんどの部分をすぐに書き始めることができます。`.app` ファイル、カウンター、ライブラリ、スーパーバイザーは比較的単純なはずです。一方、ディスパッチモジュールは、価値のあるものにしたい場合、いくつかの複雑なタスクを実行する必要があります。アプリファイルから始めましょう。
{application, erlcount,
[{vsn, "1.0.0"},
{modules, [erlcount, erlcount_sup, erlcount_lib,
erlcount_dispatch, erlcount_counter]},
{applications, [ppool]},
{registered, [erlcount]},
{mod, {erlcount, []}},
{env,
[{directory, "."},
{regex, ["if\\s.+->", "case\\s.+\\sof"]},
{max_files, 10}]}
]}.
このアプリファイルは、`ppool` のものよりも少し複雑です。それでも、いくつかのフィールドは同じであることがわかります。このアプリもバージョン 1.0.0 で、リストされているモジュールはすべて上記と同じです。次の部分は、以前にはなかったものです。アプリケーションの依存関係です。前述のように、`applications` タプルは、`erlcount` の前に開始する必要があるすべてのアプリケーションのリストを提供します。それなしで開始しようとすると、エラーメッセージが表示されます。次に、`{registered, [erlcount]}` を使用して登録済みプロセスをカウントする必要があります。技術的には、`erlcount` アプリの一部として開始されたモジュールには名前は必要ありません。私たちが行うことはすべて匿名にすることができます。ただし、`ppool` が `ppool_serv` を指定した名前に登録すること、およびプロセスプールを使用することを知っているため、`erlcount` と呼び、そこにメモします。`ppool` を使用するすべてのアプリケーションが同じことを行う場合、将来の競合を検出できるはずです。`mod` タプルは以前と同様です。アプリケーションの動作コールバックモジュールをそこで定義します。

ここで最後に新しいのは `env` タプルです。前述のように、このタプル全体は、アプリケーション固有の構成変数のキー/値ストアを提供します。これらの変数は、アプリケーション内で実行されているすべてのプロセスからアクセスでき、利便性のためにメモリに格納されます。基本的には、アプリの代替構成ファイルとして使用できます。
この場合、3 つの変数を定義します。`directory` は、アプリが `.erl` ファイルを検索する場所を示します(erlcount-1.0 ディレクトリからアプリを実行すると仮定すると、これは `learn-you-some-erlang` ルート を意味します)。次に、`max_files` は、一度に開くファイル記述子の数を示します。10,000 個のファイルを開くことになった場合、一度にすべてを開きたくないため、この変数は `ppool` のワーカーの最大数と一致します。そして、最も複雑な変数は `regex` です。これは、結果をカウントするために各ファイルに対して実行したいすべての正規表現のリストを含みます。
Perl 互換正規表現 の構文については詳しく説明しません(興味がある場合は、`re` モジュールにドキュメントが含まれています)が、ここで何をしているのかを説明します。この場合、最初の正規表現は、「`if` の後に任意の単一の空白文字(`\s`、エスケープ用に 2 番目のバックスラッシュを使用)が続き、`->` で終わる文字列を探す」と言っています。さらに、「`if` と `->` の間には何でもかまいません(`.+`)」と言っています。2 番目の正規表現は、「`case` の後に任意の単一の空白文字(`\s`)が続き、単一の空白文字が前に付いた `of` で終わる文字列を探す」と言っています。「`case ` と ` of` の間には何でもかまいません(`.+`)」と言っています。単純にするために、ライブラリで `case ... of` を使用する回数と `if ... end` を使用する回数をカウントしてみます。
クールエイドを飲みすぎないでください
正規表現を使用することは、Erlang コードを分析するための最適な選択肢ではありません。問題は、結果が不正確になるケースがたくさんあることです。テキストやコメントに、検索しているパターンと一致するが、技術的にはコードではない文字列が含まれている場合などです。
より正確な結果を得るには、Erlang で直接、モジュールの解析済みバージョンと展開バージョンを確認する必要があります。より複雑ですが(このテキストの範囲外です)、これにより、マクロなどのすべてを処理し、コメントを除外し、一般的に正しい方法で処理できるようになります。
このファイルが邪魔にならないようになったので、アプリケーションコールバックモジュールを開始できます。複雑ではなく、基本的にスーパーバイザーを開始するだけです。
-module(erlcount).
-behaviour(application).
-export([start/2, stop/1]).
start(normal, _Args) ->
erlcount_sup:start_link().
stop(_State) ->
ok.
そして、スーパーバイザー自体です。
-module(erlcount_sup).
-behaviour(supervisor).
-export([start_link/0, init/1]).
start_link() ->
supervisor:start_link(?MODULE, []).
init([]) ->
MaxRestart = 5,
MaxTime = 100,
{ok, {{one_for_one, MaxRestart, MaxTime},
[{dispatch,
{erlcount_dispatch, start_link, []},
transient,
60000,
worker,
[erlcount_dispatch]}]}}.
これは標準のスーパーバイザーであり、前の小さなスキーマに示されているように、`erlcount_dispatch` のみを担当します。シャットダウンの MaxRestart、MaxTime、および 60 秒の値はかなりランダムに選択されましたが、実際の場合はニーズを検討する必要があります。これはデモアプリケーションであるため、当時はそれほど重要ではないようでした。著者は怠惰である権利を保持しています。
チェーンの次のプロセスとモジュールであるディスパッチャーに進むことができます。ディスパッチャーは、役立つために満たす必要のあるいくつかの複雑な要件があります。
- ` で終わるファイルを検索するためにディレクトリを移動する場合。erl` は、複数の正規表現を適用する場合でも、ディレクトリのリスト全体を 1 回だけ通過する必要があります。
- 基準に一致するファイルが見つかり次第、結果カウントのスケジュールを開始できる必要があります。完全なリストを待つ必要はありません。
- 正規表現ごとにカウンターを保持する必要があるため、最終的に結果を比較できます。
- `.erl` ファイルの検索が完了する前に、`erlcount_counter` ワーカーから結果を取得し始める可能性があります。
- 多くの `erlcount_counter` が同時に実行されている可能性があります。
- ディレクトリでのファイルの検索が完了した後も、結果を取得し続ける可能性があります(特に、ファイルが多い場合や正規表現が複雑な場合)。
今すぐ考慮すべき 2 つの大きなポイントは、再帰中に結果を取得してスケジュールできるようにディレクトリをどのように移動するか、そして混乱することなく結果を受け入れる方法です。
一見すると、再帰の途中で結果を返すことができる最も簡単な方法は、プロセスを使用することです。ただし、スーパービジョツリーに別のプロセスを追加できるようにするためだけに、以前の構造を変更し、それらを連携させるのは少し面倒です。実際には、もっと簡単な方法があります。
これは、*継続渡しスタイル* と呼ばれるプログラミングスタイルです。その背後にある基本的な考え方は、通常は深く再帰的な 1 つの関数を取り、すべての手順を分解することです。各ステップ(通常はアキュムレータ)を返し、その後も続行できる関数を返します。この場合、関数は基本的に 2 つの可能な戻り値を持ちます。
{continue, Name, NextFun}
done
最初の値を受け取るたびに、FileName を `ppool` にスケジュールし、NextFun を呼び出してさらにファイルを探し続けることができます。この関数を erlcount_lib に実装できます。
-module(erlcount_lib).
-export([find_erl/1]).
-include_lib("kernel/include/file.hrl").
%% Finds all files ending in .erl
find_erl(Directory) ->
find_erl(Directory, queue:new()).
ああ、何か新しいものがあります!なんて驚きでしょう、私の心臓はドキドキし、血液はドキドキしています。上記のインクルードファイルは、`file` モジュールによって提供されたものです。ファイルの種類、サイズ、権限などを説明するフィールドを含むレコード(`#file_info{}`)が含まれています。
ここでの設計にはキューが含まれています。それはなぜでしょうか?ディレクトリに複数のファイルが含まれている可能性は十分にあります。そのため、ディレクトリにアクセスして 15 個のファイルなどが含まれている場合、最初のファイルを処理し(ディレクトリの場合は開いて内部を確認するなど)、残りの 14 個を後で処理します。そのためには、名前をメモリに保存しておけば、処理する時間まで保存されます。 dafür eine Warteschlange verwenden, aber ein Stapel oder eine andere Datenstruktur wäre auch in Ordnung, da uns die Reihenfolge, in der wir Dateien lesen, egal ist. Jedenfalls ist der Punkt, dass diese Warteschlange ein bisschen wie eine To-Do-Liste für Dateien in unserem Algorithmus fungiert.
それでは、最初の呼び出しから渡された最初のファイルの読み取りから始めましょう。
%%% Private
%% Dispatches based on file type
find_erl(Name, Queue) ->
{ok, F = #file_info{}} = file:read_file_info(Name),
case F#file_info.type of
directory -> handle_directory(Name, Queue);
regular -> handle_regular_file(Name, Queue);
_Other -> dequeue_and_run(Queue)
end.
この関数は、いくつかのことを示しています。通常のファイルとディレクトリのみを処理したいと考えています。それぞれの場合において、これらの特定のオカレンスを処理するための関数(`handle_directory/2` と `handle_regular_file/2`)を記述します。他のファイルについては、`dequeue_and_run/1` を使用して、以前に準備したものをデキューします(これがすぐにどうなるかを見ていきます)。今のところ、最初にディレクトリの処理から始めます。
%% Opens directories and enqueues files in there
handle_directory(Dir, Queue) ->
case file:list_dir(Dir) of
{ok, []} ->
dequeue_and_run(Queue);
{ok, Files} ->
dequeue_and_run(enqueue_many(Dir, Files, Queue))
end.
そのため、ファイルがない場合は `dequeue_and_run/1` で検索を続け、ファイルが多い場合は、そうする前にそれらをエンキューします。これを説明させてください。関数 `dequeue_and_run` は、ファイル名のキューを取得し、そこから 1 つの要素を取得します。そこからフェッチされたファイル名は、`find_erl(Name, Queue)` を呼び出すことによって使用され、開始したかのように続行します。
%% Pops an item from the queue and runs it.
dequeue_and_run(Queue) ->
case queue:out(Queue) of
{empty, _} -> done;
{{value, File}, NewQueue} -> find_erl(File, NewQueue)
end.
キューが空の場合(`{empty, _}`)、関数は自身を `done`(CPS 関数用に選択されたキーワード)と見なし、そうでない場合は、もう一度続行することに注意してください。
考慮しなければならなかったもう 1 つの関数は `enqueue_many/3` でした。これは、特定のディレクトリで見つかったすべてのファイルをエンキューするように設計されており、次のように機能します。
%% Adds a bunch of items to the queue.
enqueue_many(Path, Files, Queue) ->
F = fun(File, Q) -> queue:in(filename:join(Path,File), Q) end,
lists:foldl(F, Queue, Files).
基本的に、関数 `filename:join/2` を使用して、ディレクトリのパスを各ファイル名にマージします(完全なパスを取得するため)。次に、この新しいフルパスをファイルにキューに追加します。fold を使用して、特定のディレクトリ内のすべてのファイルで同じ手順を繰り返します。それから得られる新しいキューは、`find_erl/2` を再度実行するために使用されますが、今回は、見つかったすべての新しいファイルが To Do リストに追加されます。
うわー、少し脱線しました。どこまで話しましたっけ?ああ、そうです。ディレクトリを処理していて、これで完了です。次に、通常のファイルと、それらが `.erl` で終わるかどうかを確認する必要があります。
%% Checks if the file finishes in .erl
handle_regular_file(Name, Queue) ->
case filename:extension(Name) of
".erl" ->
{continue, Name, fun() -> dequeue_and_run(Queue) end};
_NonErl ->
dequeue_and_run(Queue)
end.
もし名前が(filename:extension/1 に従って)一致する場合、継続を返すことがわかります。継続は呼び出し元に Name を渡し、次に訪問するファイルのキューを持つ操作 dequeue_and_run/1 を関数でラップします。こうすることで、ユーザーはその関数を呼び出し、再帰呼び出しの中にいるかのように処理を継続しながら、同時に結果を取得できます。ファイル名が .erl で終わらない場合、ユーザーは私たちがまだ結果を返すことに関心がないため、より多くのファイルをデキューして処理を続けます。以上です。
やったー、CPS の部分は完了です。それでは、もう一つの問題に焦点を当てましょう。ディスパッチャをどのように設計すれば、ディスパッチと受信を同時に行えるようにできるでしょうか?私が提案するのは、あなたがきっと受け入れてくれるでしょうが(私がこのテキストを書いているので)、有限状態機械を使用することです。これには2つの状態があります。1つ目は「ディスパッチ」状態です。これは、find_erl CPS 関数が done エントリに到達するのを待っているときに使用されます。この状態にいる間は、カウントが完了したかどうかは考えません。それは2番目で最後の状態である「リスニング」状態でのみ発生しますが、それでも ppool からは常に通知を受け取ります。
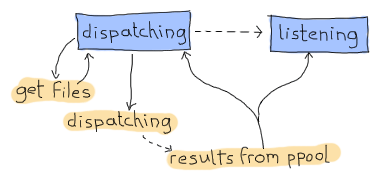
そのため、以下が必要になります。
- ディスパッチする新しいファイルを取得したときの非同期イベントを持つディスパッチ状態
- 新しいファイルの取得が完了したときの非同期イベントを持つディスパッチ状態
- 新しいファイルの取得が完了したときの非同期イベントを持つリスニング状態
- ppool ワーカーが正規表現の実行を完了したときに送信されるグローバルイベント。
それでは、gen_fsm を少しずつ構築していきましょう。
-module(erlcount_dispatch).
-behaviour(gen_fsm).
-export([start_link/0, complete/4]).
-export([init/1, dispatching/2, listening/2, handle_event/3,
handle_sync_event/4, handle_info/3, terminate/3, code_change/4]).
-define(POOL, erlcount).
API には、スーパーバイザー用の関数(start_link/0)と ppool 呼び出し元用の関数(complete/4、引数は後で説明します)の2つの関数があります。その他の関数は、非同期状態ハンドラーである listening/2 と dispatching/2 を含む、標準の gen_fsm コールバックです。また、ppool サーバーに 'erlcount' という名前を付けるために使用される ?POOL マクロも定義しました。
しかし、gen_fsm のデータはどのようなものになるでしょうか?非同期で動作し、常に ppool:run_async/2 を呼び出すため、ファイルのスケジュールが完了したかどうかを知る方法がありません。基本的には、以下のようなタイムラインになる可能性があります。
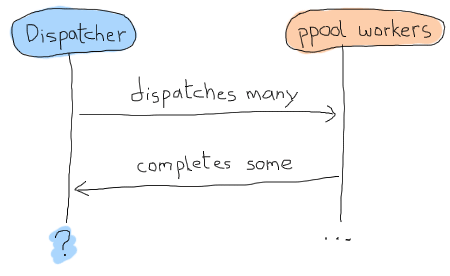
この問題を解決する一つの方法はタイムアウトを使用することですが、これは常に厄介です。タイムアウトは長すぎるのか短すぎるのか?何かがクラッシュしたのか?このような不確実性は、レモンで作られた歯ブラシと同じくらい楽しくありません。代わりに、各ワーカーに何らかのIDを与え、それを追跡して返信と関連付けるという概念を使用できます。「成功したワーカー」のプライベートクラブに入るための秘密のパスワードのようなものです。この概念により、受信するメッセージを1対1で照合し、いつ確実に完了したかを知ることができます。これで、状態データがどのように見えるかがわかりました。
-record(data, {regex=[], refs=[]}).
最初のリストは {RegularExpression, NumberOfOccurrences} 形式のタプルで、2番目のリストは何らかのメッセージへの参照のリストです。一意であれば何でも構いません。次に、次の2つのAPI関数を追加できます。
%%% PUBLIC API
start_link() ->
gen_fsm:start_link(?MODULE, [], []).
complete(Pid, Regex, Ref, Count) ->
gen_fsm:send_all_state_event(Pid, {complete, Regex, Ref, Count}).
そして、これが秘密の complete/4 関数です。当然のことながら、ワーカーは3つのデータを送り返すだけで済みます。実行していた正規表現、関連付けられたスコア、そして上記の参照です。素晴らしい、これで本当に興味深い部分に取り組むことができます!
init([]) ->
%% Move the get_env stuff to the supervisor's init.
{ok, Re} = application:get_env(regex),
{ok, Dir} = application:get_env(directory),
{ok, MaxFiles} = application:get_env(max_files),
ppool:start_pool(?POOL, MaxFiles, {erlcount_counter, start_link, []}),
case lists:all(fun valid_regex/1, Re) of
true ->
self() ! {start, Dir},
{ok, dispatching, #data{regex=[{R,0} || R <- Re]}};
false ->
{stop, invalid_regex}
end.
init 関数は、まずアプリケーションファイルから実行に必要なすべての情報をロードします。それが完了したら、erlcount_counter をコールバックモジュールとしてプロセスプールを開始する予定です。実際に開始する前の最後のステップは、すべての正規表現が有効であることを確認することです。その理由は簡単です。ここでチェックしないと、どこかでエラー処理の呼び出しを追加する必要があります。これはおそらく erlcount_counter ワーカーで行われるでしょう。そこでエラーが発生した場合、ワーカーがクラッシュしたときにどうするかなどを定義する必要があります。アプリケーションの起動時に処理する方が簡単です。valid_regex/1 関数は次のとおりです。
valid_regex(Re) ->
try re:run("", Re) of
_ -> true
catch
error:badarg -> false
end.
空の文字列に対してのみ正規表現を実行しようとします。これには時間がかからず、re モジュールが実行を試みることができます。正規表現が有効であれば、自分自身に {start, Directory} を送信し、[{R,0} || R <- Re] で定義された状態でアプリケーションを開始します。これは基本的に [a,b,c] 形式のリストを [{a,0},{b,0},{c,0}] 形式に変更します。各正規表現にカウンターを追加するという考え方です。
handle_info/2 で処理する必要がある最初のメッセージは {start, Dir} です。Erlang のビヘイビアはほとんどすべてメッセージに基づいているため、関数呼び出しをトリガーして自分のやり方で処理を行う場合は、自分自身にメッセージを送信するという面倒な手順を実行する必要があることを忘れないでください。面倒ですが、管理できます。
handle_info({start, Dir}, State, Data) ->
gen_fsm:send_event(self(), erlcount_lib:find_erl(Dir)),
{next_state, State, Data}.
自分自身に erlcount_lib:find_erl(Dir) の結果を送信します。これは、FSM の init 関数によって設定された State の値であるため、dispatching で受信されます。このスニペットは問題を解決するだけでなく、FSM 全体にわたる一般的なパターンを示しています。find_erl/1 関数は継続渡しスタイルで記述されているため、非同期イベントを自分自身に送信し、適切なコールバック状態で処理できます。継続の最初の結果は {continue, File, Fun} になる可能性があります。また、init 関数で初期状態として設定したため、「ディスパッチ」状態になります。
dispatching({continue, File, Continuation}, Data = #data{regex=Re, refs=Refs}) ->
F = fun({Regex, _Count}, NewRefs) ->
Ref = make_ref(),
ppool:async_queue(?POOL, [self(), Ref, File, Regex]),
[Ref|NewRefs]
end,
NewRefs = lists:foldl(F, Refs, Re),
gen_fsm:send_event(self(), Continuation()),
{next_state, dispatching, Data#data{refs = NewRefs}};
これは少し醜いです。各正規表現について、一意の参照を作成し、この参照を認識する ppool ワーカーをスケジュールし、次にこの参照を保存します(ワーカーが終了したかどうかを知るため)。すべての新しい参照を簡単に累積できるように、foldl でこれを行うことにしました。ディスパッチが完了したら、継続を再度呼び出してさらに結果を取得し、新しい参照を状態として次のメッセージを待ちます。
次にどのような種類のメッセージを受信できるでしょうか?ここでは2つの選択肢があります。ワーカーから結果が返されていないか(まだ実装されていない場合でも)、すべてのファイルが検索されたため done メッセージを受信するかのいずれかです。2番目のタイプに進み、dispatching/2 関数の実装を完了しましょう。
dispatching(done, Data) ->
%% This is a special case. We can not assume that all messages have NOT
%% been received by the time we hit 'done'. As such, we directly move to
%% listening/2 without waiting for an external event.
listening(done, Data).
コメントには何が起こっているかが明示的に書かれていますが、とにかく説明させてください。ジョブをスケジュールすると、dispatching/2 または listening/2 の状態で結果を受信できます。これは次の形式をとることができます。
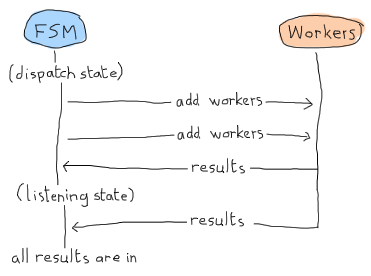
この場合、「リスニング」状態は結果を待つだけで、すべてが完了したと宣言できます。しかし、ここは Erlang ランド( *Erland* )であり、並列で非同期に動作することを忘れないでください!このシナリオは同じくらい可能性があります。
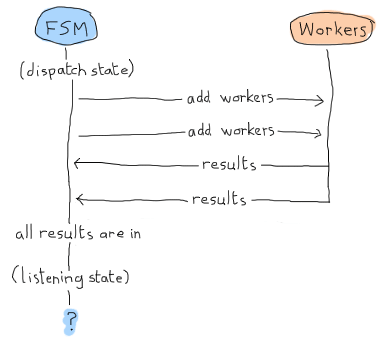
おっと。アプリケーションはメッセージを待って永遠にハングしてしまうでしょう。これが listening/2 を手動で呼び出す必要がある理由です。すべてが受信されたことを確認するために、何らかの結果検出を強制的に実行します。すでにすべての結果を受信している場合に備えてです。これがどのように見えるかを示します。
listening(done, #data{regex=Re, refs=[]}) -> % all received!
[io:format("Regex ~s has ~p results~n", [R,C]) || {R, C} <- Re],
{stop, normal, done};
listening(done, Data) -> % entries still missing
{next_state, listening, Data}.
残りの *refs* がない場合、すべてが受信されたため、結果を出力できます。そうでない場合は、メッセージをリッスンし続けることができます。complete/4 とこの図をもう一度見てください。
結果メッセージは、「ディスパッチ」状態と「リスニング」状態の両方で受信できるため、グローバルです。実装は次のとおりです。
handle_event({complete, Regex, Ref, Count}, State, Data = #data{regex=Re, refs=Refs}) ->
{Regex, OldCount} = lists:keyfind(Regex, 1, Re),
NewRe = lists:keyreplace(Regex, 1, Re, {Regex, OldCount+Count}),
NewData = Data#data{regex=NewRe, refs=Refs--[Ref]},
case State of
dispatching ->
{next_state, dispatching, NewData};
listening ->
listening(done, NewData)
end.
まず、すべてのカウントも含まれている Re リストから、完了した正規表現を見つけます。その値(OldCount)を抽出し、lists:keyreplace/4 を使用して新しいカウント(OldCount+Count)で更新します。ワーカーの Ref を削除しながら、新しいスコアで Data レコードを更新し、自分自身を次の状態に送信します。
通常の FSM では、{next_state, State, NewData} を実行するだけですが、ここでは、いつ完了したかを知るという問題があるため、手動で listening/2 を再度呼び出す必要があります。面倒ですが、残念ながら必要な手順です。
これでディスパッチャは完了です。残りのフィラービヘイビア関数を追加するだけです。
handle_sync_event(Event, _From, State, Data) ->
io:format("Unexpected event: ~p~n", [Event]),
{next_state, State, Data}.
terminate(_Reason, _State, _Data) ->
ok.
code_change(_OldVsn, State, Data, _Extra) ->
{ok, State, Data}.
そして、カウンターに移ることができます。その前に少し休憩を取りたいかもしれません。ハードコアな読者は、リラックスするために自分の体重でベンチプレスを数回行ってから、戻ってきてください。
カウンター
カウンターはディスパッチャよりも単純です。処理を行うためにビヘイビア(この場合は gen_server)が必要ですが、非常にミニマルなものになります。3つのことだけを実行する必要があります。
- ファイルを開く
- 正規表現を実行してインスタンスをカウントする
- 結果を返す。
最初のポイントについては、file にはそれを支援する関数がたくさんあります。3番については、erlcount_dispatch:complete/4 を定義して実行します。2番については、re モジュールで run/2-3 を使用できますが、必要なことを完全には実行しません。
1> re:run(<<"brutally kill your children (in Erlang)">>, "a").
{match,[{4,1}]}
2> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global]).
{match,[[{4,1}],[{35,1}]]}
3> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global, {capture, all, list}]).
{match,[["a"],["a"]]}
4> re:run(<<"brutally kill your children (in Erlang)">>, "child", [global, {capture, all, list}]).
{match,[["child"]]}
必要な引数(re:run(String, Pattern, Options))をとりますが、正しいカウントは得られません。カウンターの記述を開始できるように、erlcount_lib に次の関数を追加しましょう。
regex_count(Re, Str) ->
case re:run(Str, Re, [global]) of
nomatch -> 0;
{match, List} -> length(List)
end.
これは基本的に結果をカウントして返すだけです。エクスポートフォームに追加することを忘れないでください。
さて、ワーカー に進みましょう。
-module(erlcount_counter).
-behaviour(gen_server).
-export([start_link/4]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
terminate/2, code_change/3]).
-record(state, {dispatcher, ref, file, re}).
start_link(DispatcherPid, Ref, FileName, Regex) ->
gen_server:start_link(?MODULE, [DispatcherPid, Ref, FileName, Regex], []).
init([DispatcherPid, Ref, FileName, Regex]) ->
self() ! start,
{ok, #state{dispatcher=DispatcherPid,
ref = Ref,
file = FileName,
re = Regex}}.
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(start, S = #state{re=Re, ref=Ref}) ->
{ok, Bin} = file:read_file(S#state.file),
Count = erlcount_lib:regex_count(Re, Bin),
erlcount_dispatch:complete(S#state.dispatcher, Re, Ref, Count),
{stop, normal, S}.
terminate(_Reason, _State) ->
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
ここで興味深いセクションは2つあります。開始するように指示する init/1 コールバックと、ファイルを開き(file:read_file(Name))、バイナリを取得し、新しい regex_count/2 関数に渡し、complete/4 で送り返す単一の handle_info/2 句です。その後、ワーカーを停止します。残りは標準の OTP コールバックです。
これで全体をコンパイルして実行できます!
$ erl -make Recompile: src/erlcount_sup Recompile: src/erlcount_lib Recompile: src/erlcount_dispatch Recompile: src/erlcount_counter Recompile: src/erlcount Recompile: test/erlcount_tests
素晴らしい。シャンパンを開けましょう、文句はありません!
アプリケーションの実行
アプリケーションを実行するには多くの方法があります。これらの2つのディレクトリが隣り合っているディレクトリにいることを確認してください。
erlcount-1.0 ppool-1.0
次に、Erlang を次の方法で起動します。
$ erl -env ERL_LIBS "."
ERL_LIBS 変数は、環境で定義された特別な変数であり、Erlang が OTP アプリケーションを見つけることができる場所を指定できます。VM は、そこで自動的に ebin/ ディレクトリを検索できます。erl は、この設定をすばやくオーバーライドするために -env NameOFVar Value 形式の引数をとることもできるため、ここではそれを使用しました。 ERL_LIBS 変数は、特にライブラリをインストールするときに非常に便利なので、覚えておいてください!
起動した VM で、すべてのモジュールが存在することをテストできます。
1> application:load(ppool). ok
この関数は、見つかった場合にすべてのアプリケーションモジュールをメモリにロードしようとします。呼び出さないと、アプリケーションの起動時に自動的に実行されますが、これはパスをテストする簡単な方法を提供します。アプリを起動できます。
2> application:start(ppool), application:start(erlcount). ok Regex if\s.+-> has 20 results Regex case\s.+\sof has 26 results
結果は、ディレクトリの内容によって異なる場合があります。ファイルの数によっては、時間がかかる場合があることに注意してください。

しかし、アプリケーションに異なる変数を設定したい場合はどうでしょうか?アプリケーションファイルを常に変更する必要がありますか?いいえ、必要ありません!Erlang はそれもサポートしています。たとえば、Erlang プログラマーがソースファイルで何回怒っているかを確認したいとしましょうか?
erl 実行ファイルは、-AppName Key1 Val1 Key2 Val2 ... KeyN ValN の形式の特別な引数セットをサポートしています。この場合、R14B02 ディストリビューションの Erlang ソースコードに対して、以下のように2つの正規表現を使用して正規表現を実行できます。
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["shit","damn"]' ... 1> application:start(ppool), application:start(erlcount). ok Regex shit has 3 results Regex damn has 1 results 2> q(). ok
この場合、引数として指定するすべての式は、単一引用符(')で囲まれていることに注意してください。これは、Unix シェルでリテラルとして扱われるようにするためです。シェルによってルールが異なる場合があります。
より一般的な式(値が大文字で始まることを許可する)と、より多くのファイル記述子を許可する式を使用して検索を試みることもできます。
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["[Ss]hit","[Dd]amn"]' max_files 50 ... 1> application:start(ppool), application:start(erlcount). ok Regex [Ss]hit has 13 results Regex [Dd]amn has 6 results 2> q(). ok
ああ、OTP プログラマーたち。なぜそんなに怒っているのですか?(「Erlang での作業」は許容できる回答ではありません)
これは、数百ものファイルに対してより複雑なチェックが必要になるため、実行にさらに時間がかかる場合があります。これはすべて非常にうまく機能しますが、いくつかの厄介な点があります。なぜ私たちは常に両方のアプリケーションを手動で開始する必要があるのでしょうか?もっと良い方法はないのでしょうか?
含まれるアプリケーション
含まれるアプリケーションは、物事を機能させるための1つの方法です。含まれるアプリケーションの基本的な考え方は、アプリケーション(この場合は ppool)を別のアプリケーション(ここでは erlcount)の一部として定義することです。これを行うには、両方のアプリケーションに多くの変更を加える必要があります。
要点は、アプリケーションファイルを少し変更し、_スタートフェーズ_と呼ばれるものを追加する必要があることです。

含まれるアプリケーションを使用 **しない** ことを強くお勧めする理由は、コードの再利用性が著しく制限されるためです。このように考えてください。私たちは、誰もが ppool を使用し、独自のプールを取得し、自由に使用できるようにするために、ppool のアーキテクチャの開発に多くの時間を費やしました。もし、それを含まれるアプリケーションにプッシュすると、この VM 上の他のアプリケーションに含めることができなくなり、erlcount が停止すると、ppool も停止し、ppool を使用したいサードパーティアプリケーションの作業が台無しになります。
これらの理由から、含まれるアプリケーションは、多くの Erlang プログラマーのツールボックスから除外されることがよくあります。次の章で説明するように、リリースは基本的に同じこと(そしてさらに多くのこと)をより一般的な方法で行うのに役立ちます。
その前に、アプリケーションについてもう1つ議論すべきトピックがあります。
複雑な終了
アプリケーションを終了する前に、より多くの手順を実行する必要がある場合があります。アプリケーションコールバックモジュールの stop/1 関数は、アプリケーションがすでに終了した **後** に呼び出されるため、特に十分ではない場合があります。アプリケーションが実際に終了する前にクリーンアップする必要がある場合はどうすればよいでしょうか?
秘訣は簡単です。アプリケーションコールバックモジュールに prep_stop(State) 関数を追加するだけです。 State は start/2 関数によって返された状態であり、prep_stop/1 が返すものは何でも stop/1 に渡されます。したがって、prep_stop/1 関数は技術的には start/2 と stop/1 の間に挿入され、アプリケーションがまだ生きている間に実行されますが、シャットダウン直前です。
これは、使用する必要があるときにわかる種類のコールバックですが、今のところアプリケーションには必要ありません。
飲みすぎないでください(誇大広告に惑わされないでください)prep_stop/1 コールバックの実際のユースケースは、Yurii Rashkosvkii (yrashk) が Erlang のパッケージマネージャーである agner の問題をデバッグするのを手伝っていたときに発生しました。発生した問題は少し複雑で、simple_one_for_one スーパーバイザーとアプリケーションマスター間の奇妙な相互作用に関係しているため、この部分はスキップして構いません。
Agner は基本的に、アプリケーションが起動し、トップレベルのスーパーバイザーを起動し、それがサーバーと別のスーパーバイザーを起動し、それが動的な子プロセスを生成するという構造になっています。
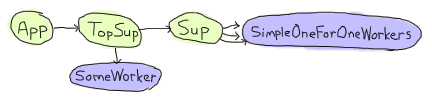
問題は、ドキュメントに次のように書かれていることです。
simple-one-for-one スーパーバイザーに関する重要な注意事項:simple-one-for-one スーパーバイザーの動的に作成された子プロセスは、シャットダウン戦略に関係なく明示的に kill されませんが、スーパーバイザーが終了したとき(つまり、親プロセスからの終了シグナルを受信したとき)に終了することが期待されます。
そして実際、それらは kill されません。スーパーバイザーは通常の子供を kill して消え、simple-one-for-one の子供の動作が終了メッセージをキャッチして去るようにします。これ自体は問題ありません。
前述のように、各アプリケーションにはアプリケーションマスターがあります。このアプリケーションマスターはグループリーダーとして機能します。思い出してくださいが、アプリケーションマスターは親(アプリケーションコントローラー)とその直接の子(アプリのトップレベルスーパーバイザー)の両方にリンクされ、両方を監視します。どちらかが失敗すると、マスターは独自の実行を終了し、グループリーダーとしてのステータスを使用して残りのすべての子を終了します。繰り返しますが、これ自体は問題ありません。
ただし、両方の機能を混在させて、application:stop(agner) でアプリケーションをシャットダウンすることにすると、非常に厄介な状況に陥ります。
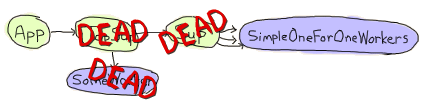
このまさにその時点で、両方のスーパーバイザーは、アプリの通常のワーカーと同様に、死んでいます。simple-one-for-one ワーカーは現在、直接の祖先によって送信された EXIT シグナルをキャッチして、それぞれが死にかけています。
しかし同時に、アプリケーションマスターは直接の子が死にかけていることに気づき、まだ死んでいない simple-one-for-one ワーカー全員を kill してしまいます。
その結果、後片付けに成功したワーカーと、そうでなかったワーカーが混在することになります。これはタイミングに大きく依存し、デバッグが難しく、修正が簡単です。
Yurii と私は、基本的に ApplicationCallback:prep_stop(State) 関数を使用して、すべての動的な simple-one-for-one 子のリストを取得し、それらを監視し、stop(State) コールバック関数でそれらすべてが死ぬのを待つことで、これを修正しました。これにより、アプリケーションコントローラーは、すべての動的な子が死ぬまで存続し続けることができます。実際のファイルは、Agner の github リポジトリ にあります。

なんて醜いのでしょう!うまくいけば、人々はめったにこの種の問題に遭遇することはなく、あなたも遭遇しないことを願っています。prep_stop/1 を使用して物事を機能させるという恐ろしいイメージを洗い流すために、石鹸で目を洗うことができます。ただし、それが理にかなっていて望ましい場合もあります。あなたが戻ってきたら、アプリケーションをリリースにパッケージ化することを考え始めます。
更新
バージョン R15B 以降、上記の問題は解決されました。スーパーバイザーのシャットダウンの場合、動的な子の終了は同期的に見えるようになりました。