始め方(本当に)
Erlangは比較的小さくシンプルな言語です(C++よりもCの方がシンプルであるのと同じように)。言語にはいくつかの基本的なデータ型が組み込まれており、そのため、この章ではそれらのほとんどを扱います。これは、後でErlangで記述するすべてのプログラムの基礎を説明しているので、読むことを強くお勧めします。
数値
Erlangシェルでは、**式はピリオドと空白(改行、スペースなど)で終わらせる必要があります。** そうしないと、実行されません。式はコンマで区切ることができますが、最後の式の結果のみが表示されます(他の式も実行されます)。これはほとんどの人にとって確かに珍しい構文であり、Erlangが論理プログラミング言語であるPrologで直接実装された時代から来ています。
前の章で説明したようにErlangシェルを開き、これらのものを入力してみましょう!
1> 2 + 15. 17 2> 49 * 100. 4900 3> 1892 - 1472. 420 4> 5 / 2. 2.5 5> 5 div 2. 2 6> 5 rem 2. 1
Erlangは浮動小数点数と整数のどちらを入力しても問題ないことに気付いているはずです。算術演算を行う場合、両方の型がサポートされています。 整数と浮動小数点数は、Erlangの数学演算子が透過的に処理するデータ型です。ただし、整数同士の除算を行うには`div`を使用し、剰余演算子を使用するには`rem`(剰余)を使用します。
整数と浮動小数点数は、Erlangの数学演算子が透過的に処理するデータ型です。ただし、整数同士の除算を行うには`div`を使用し、剰余演算子を使用するには`rem`(剰余)を使用します。
1つの式に複数の演算子を使用でき、数学演算は通常の優先順位規則に従うことに注意してください。
7> (50 * 100) - 4999. 1 8> -(50 * 100 - 4999). -1 9> -50 * (100 - 4999). 244950
10進数以外の基数で整数を表現するには、`Base#Value`として入力します(Baseは2〜36の範囲内)。
10> 2#101010. 42 11> 8#0677. 447 12> 16#AE. 174
素晴らしい!Erlangには、デスクの隅にある電卓の機能があり、さらに奇妙な構文が追加されています!非常にエキサイティングです!
不変の変数
算術演算は良いですが、結果をどこかに保存できなければ、それほど遠くには行けません。そのため、変数を使用します。この本の序文を読んだことがあるなら、関数型プログラミングでは変数が変数になり得ないことを知っているでしょう。変数の基本的な動作は、これらの7つの式で示すことができます(変数は大文字で始まることに注意してください)。
1> One. * 1: variable 'One' is unbound 2> One = 1. 1 3> Un = Uno = One = 1. 1 4> Two = One + One. 2 5> Two = 2. 2 6> Two = Two + 1. ** exception error: no match of right hand side value 3 7> two = 2. ** exception error: no match of right hand side value 2
これらのコマンドが最初に教えてくれるのは、変数に値を一度だけ割り当てることができるということです。その後、すでに同じ値を持っている場合、変数に値を「ふりをする」ことができます。異なる場合は、Erlangはエラーを発生させます。これは正しい観察ですが、説明はもう少し複雑で、`=`演算子に依存します。`=`演算子(変数ではない)は、値を比較し、値が異なる場合はエラーを発生させる役割を果たします。同じ値の場合は、その値を返します。
8> 47 = 45 + 2. 47 9> 47 = 45 + 3. ** exception error: no match of right hand side value 48
この演算子が変数と組み合わされるときの動作は、左辺の項が変数であり、束縛されていない(関連付けられた値がない)場合、Erlangは自動的に右辺の値を左辺の変数にバインドします。その結果、比較は成功し、変数はメモリに値を保持します。
`=`演算子のこの動作は、「パターンマッチング」と呼ばれるものの基礎であり、多くの関数型プログラミング言語が備えています。ただし、Erlangの方法はやや柔軟で完全であると一般的に考えられています。この章でタプル型とリスト型を扱い、次の章で関数を扱う際に、パターンマッチングについてより詳細に見ていきます。
コマンド1〜7が教えてくれるもう1つのことは、変数名は必ず大文字で始める必要があるということです。コマンド7は、`two`という単語が小文字で始まっていたため失敗しました。技術的には、変数はアンダースコア('_')で始めることもできますが、慣例により、その使用は気にしない値に制限されていますが、それが何を含んでいるかを文書化することが必要だと感じました。
アンダースコアだけの変数を持つこともできます。
10> _ = 14+3. 17 11> _. * 1: variable '_' is unbound
他の種類の変数とは異なり、決して値を格納しません。現時点では全く役に立ちませんが、必要になったときに存在することを知っておくでしょう。
**注:** シェルでテストしていて、変数に間違った値を保存した場合、`f(Variable)。`関数を使用してその変数を「消去」することができます。すべての変数名をクリアする場合は、`f()。`を実行します。
これらの関数はテスト時のみに役立ち、シェルでのみ機能します。実際のプログラムを作成する場合、そのような方法で値を破棄することはできません。シェルでのみ実行できることは、Erlangが産業環境で使用できることを認めれば理にかなっています。何年も中断することなくアクティブなシェルを持つことは十分に可能です...その期間中に変数`X`が複数回使用されると予想しましょう。
アトム
変数名が小文字で始まらない理由があります。それはアトムです。アトムはリテラルであり、値に独自の名称を持つ定数です。見たままがすべてであり、それ以上は期待できません。アトム`cat`は「cat」を意味し、それだけのことです。それといじくり回すことはできません。変更も破壊もできません。それは`cat`です。受け入れましょう。
小文字で始まる単一の単語はアトムを書く方法ですが、それ以外にも方法があります。
1> atom. atom 2> atoms_rule. atoms_rule 3> atoms_rule@erlang. atoms_rule@erlang 4> 'Atoms can be cheated!'. 'Atoms can be cheated!' 5> atom = 'atom'. atom
アトムは、小文字で始まらない場合、または英数字、アンダースコア(_)、または@以外の文字が含まれている場合は、単一引用符(')で囲む必要があります。
式5は、単一引用符付きのアトムと、それらがない同様のアトムが完全に同じであることを示しています。
アトムを、値として名前を持つ定数と比較しました。以前に定数を使用したコードで作業したことがあるかもしれません。例として、目の色の値があるとします。 `BLUE -> 1, BROWN -> 2, GREEN -> 3, OTHER -> 4`。定数の名前を何らかの基礎となる値に一致させる必要があります。アトムを使用すると、基礎となる値を無視できます。目の色は単に'blue'、'brown'、'green'、'other'にすることができます。これらの色はコードのどこでも使用できます。基礎となる値は決して衝突せず、そのような定数が未定義になることはありません!値が関連付けられた定数が本当に必要な場合は、第4章(モジュール)で説明する方法があります。
`BLUE -> 1, BROWN -> 2, GREEN -> 3, OTHER -> 4`。定数の名前を何らかの基礎となる値に一致させる必要があります。アトムを使用すると、基礎となる値を無視できます。目の色は単に'blue'、'brown'、'green'、'other'にすることができます。これらの色はコードのどこでも使用できます。基礎となる値は決して衝突せず、そのような定数が未定義になることはありません!値が関連付けられた定数が本当に必要な場合は、第4章(モジュール)で説明する方法があります。
したがって、アトムは主に、それに関連付けられたデータを表現または修飾するために役立ちます。単独で使用すると、良い用途を見つけるのは少し難しいです。そのため、それらで遊ぶのに多くの時間を費やすことはありません。それらの最適な用途は、他の種類のデータと組み合わせた場合です。
クーレイドを飲みすぎないでください
アトムは非常に優れており、メッセージの送信や定数の表現に最適な方法です。ただし、アトムをあまりにも多くの用途に使用すると、落とし穴があります。アトムは「アトムテーブル」で参照され、メモリを消費します(32ビットシステムではアトムあたり4バイト、64ビットシステムではアトムあたり8バイト)。アトムテーブルはガベージコレクションされません。そのため、システムがメモリ使用量または1048577個のアトムが宣言されたためにクラッシュするまで、アトムは蓄積されます。
つまり、アトムは何らかの理由で動的に生成するべきではありません。システムの信頼性を維持する必要があり、ユーザー入力が何らかの理由でアトムの作成を指示することでシステムをクラッシュさせる可能性がある場合、深刻な問題が発生します。アトムは開発者にとってのツールとして見なされるべきです。なぜなら、実際それがアトムだからです。
**注:** 一部のアトムは予約語であり、言語設計者が意図した用途(関数名、演算子、式など)を除いて使用できません。これらは次のとおりです。`after and andalso band begin bnot bor bsl bsr bxor case catch cond div end fun if let not of or orelse query receive rem try when xor`

ブール代数と比較演算子
小さくて大きいもの、真偽の区別ができないと、かなり困ることになります。他の言語と同様に、Erlangにはブール演算を使用し、アイテムを比較する方法があります。
ブール代数は非常に簡単です
1> true and false. false 2> false or true. true 3> true xor false. true 4> not false. true 5> not (true and true). false
**注:** ブール演算子`and`と`or`は、常に演算子の両側の引数を評価します。短絡演算子(必要な場合にのみ右側の引数を評価する)を使用するには、`andalso`と`orelse`を使用します。
等価性または不等価性をテストすることも非常に簡単ですが、他の多くの言語で見られるものとはわずかに異なる記号があります。
6> 5 =:= 5. true 7> 1 =:= 0. false 8> 1 =/= 0. true 9> 5 =:= 5.0. false 10> 5 == 5.0. true 11> 5 /= 5.0. false
まず、通常の言語で`==`と`!=`を使用して等価性をテストする場合、Erlangでは`=:=`と`=/=`を使用します。最後の3つの式(9行目から11行目)は、落とし穴も紹介しています。Erlangは算術演算では浮動小数点数と整数を気にしませんが、比較する場合は気にします。心配はいりません。`==`と`/=`演算子がそのような場合に役立ちます。正確な等価性が必要かどうかを覚えておくことが重要です。
比較の他の演算子には、`<`(より小さい)、`>`(より大きい)、`>=`(以上)、`=<`(以下)があります。最後のものは(私の意見では)逆であり、私のコードで多くの構文エラーの原因となっています。`=<`に注意してください。
12> 1 < 2. true 13> 1 < 1. false 14> 1 >= 1. true 15> 1 =< 1. true
`5 + llama`または`5 == true`を実行するとどうなるでしょうか?試してみて、エラーメッセージに驚かれるよりも良い方法はありません!
12> 5 + llama.
** exception error: bad argument in an arithmetic expression
in operator +/2
called as 5 + llama
まあ!Erlangは、基本的な型のいくつかを誤用することをあまり好みません!エミュレータはここで適切なエラーメッセージを返します。`+`演算子の周囲で使用されている2つの引数のいずれかを気に入らないと言っています!
ただし、Erlangが間違った型に対して怒ることは常に当てはまるわけではありません。
13> 5 =:= true. false
なぜ、一部の演算では異なる型を拒否するのに、他の演算では拒否しないのでしょうか?Erlangはあらゆるものを加算することを許可しませんが、比較することは許可します。これは、Erlangの作成者がプラグマティズムが理論を凌駕すると考え、任意の項をソートできる一般的なソートアルゴリズムを簡単に記述できることは素晴らしいことだと判断したためです。これは生活をシンプルにするものであり、ほとんどの場合そうすることができます。
ブール代数と比較を行う際に覚えておくべきことがあと1つあります。
14> 0 == false. false 15> 1 < false. true
手続き型言語やほとんどのオブジェクト指向言語を使用している場合は、髪を引っ張っている可能性があります。14行目は`true`と評価され、15行目は`false`と評価されるはずです!結局のところ、falseは0を意味し、trueはそれ以外のものを意味します!Erlangを除いて。なぜなら、私はあなたに嘘をついたからです。はい、そうしました。恥ずかしいです。
Erlangには、ブール値の`true`と`false`のようなものはありません。trueとfalseという用語はアトムですが、言語に十分に統合されているため、falseとtrueがfalseとtrue以外を意味することを期待しない限り、問題はありません。
**注:** 比較における各要素の正しい順序は次のとおりです。
数値 < アトム < 参照 < 関数 < ポート < プロセスID < タプル < リスト < ビット文字列
これらの型のすべてはまだわかりませんが、この本を通して知ることになります。これが、あらゆるものを何でも比較できる理由であることを覚えておいてください!Erlangの作成者の1人であるJoe Armstrongの言葉を借りれば、「実際の順序は重要ではありません。しかし、全順序が明確に定義されていることは重要です。」
タプル
タプルはデータを整理するための方法です。 いくつあるか分かっている多くの項をグループ化する方法です。Erlangでは、タプルは{Element1, Element2, ..., ElementN}という形式で記述されます。 例えば、デカルトグラフ上の点の位置を伝えたい場合、座標(x,y)を私に伝えるでしょう。この点を2つの項のタプルとして表現できます。
1> X = 10, Y = 4.
4
2> Point = {X,Y}.
{10,4}
この場合、点は常に2つの項になります。変数XとYをあちこちに持ち歩く代わりに、1つだけ持ち運べばよくなります。しかし、点を受け取り、X座標のみが必要な場合はどうすればよいでしょうか?その情報を抽出するのは難しくありません。値を代入したとき、Erlangは同じ値であっても文句を言わなかったことを思い出してください。それを利用しましょう!f()で設定した変数をクリアする必要があるかもしれません。
3> Point = {4,5}.
{4,5}
4> {X,Y} = Point.
{4,5}
5> X.
4
6> {X,_} = Point.
{4,5}
それ以降は、Xを使用してタプルの最初の値を取得できます!どのようにそうなったのでしょうか?  まず、XとYには値がなく、束縛されていない変数と見なされていました。
まず、XとYには値がなく、束縛されていない変数と見なされていました。=演算子の左辺でタプル{X,Y}に設定すると、=演算子は両方の値を比較します。{X,Y}対{4,5}。Erlangは、タプルから値を展開し、左辺の束縛されていない変数に分配するほど賢いです。すると、比較は{4,5} = {4,5}のみとなり、明らかに成功します!これはパターンマッチングの多くの形式の1つです。
式6では、匿名変数_を使用していることに注意してください。これはまさにそれが意図されている使用方法です。使用しないため、通常そこに配置される値を破棄するためです。_変数は常に束縛されていないと見なされ、パターンマッチングのワイルドカードとして機能します。タプルを展開するためのパターンマッチングは、要素数(タプルの長さ)が同じ場合にのみ機能します。
7> {_,_} = {4,5}.
{4,5}
8> {_,_} = {4,5,6}.
** exception error: no match of right hand side value {4,5,6}
タプルは、単一の値を扱う場合にも役立ちます。どのように?最も簡単な例は温度です。
9> Temperature = 23.213. 23.213
ええ、ビーチに行くのに良い日みたいですね…ちょっと待ってください、この温度はケルビン、摂氏、それとも華氏ですか?
10> PreciseTemperature = {celsius, 23.213}.
{celsius,23.213}
11> {kelvin, T} = PreciseTemperature.
** exception error: no match of right hand side value {celsius,23.213}
これはエラーをスローしますが、まさに私たちが望むものです!これも、再びパターンマッチングが働いています。=演算子は{kelvin, T}と{celsius, 23.213}を比較することになります。変数Tが束縛されていなくても、Erlangは比較時にcelsiusアトムをkelvinアトムと同一視しません。例外がスローされ、コードの実行が停止します。これにより、ケルビン単位の温度を期待するプログラムの部分は、摂氏で送られた温度を処理できなくなります。これにより、プログラマは送られているものが何かを簡単に知ることができ、デバッグ支援としても機能します。1つの要素が続くアトムを含むタプルは、「タグ付きタプル」と呼ばれます。タプルの任意の要素は、他のタプルも含め、任意の型にすることができます。
12> {point, {X,Y}}.
{point,{4,5}}
複数の点を持ち運びたい場合はどうすればよいでしょうか?
リストです!
リストは、多くの関数型言語の基盤です。あらゆる種類の問題を解決するために使用され、Erlangで最も使用されているデータ構造であることは間違いありません。リストには何でも含めることができます!数値、アトム、タプル、他のリスト;単一の構造体の中にあなたの最も大胆な夢を。
1> [1, 2, 3, {numbers,[4,5,6]}, 5.34, atom].
[1,2,3,{numbers,[4,5,6]},5.34,atom]
簡単ですよね?
2> [97, 98, 99]. "abc"
おっと!これはErlangで最も嫌われているものの1つです。文字列です!文字列はリストであり、表記はまったく同じです!なぜ嫌われるのでしょうか?これのせいです。
3> [97,98,99,4,5,6]. [97,98,99,4,5,6] 4> [233]. "é"
Erlangは、少なくとも1つが文字を表すことができない場合にのみ、数値のリストを数値として出力します!Erlangには本当の文字列というものは存在しません!これは間違いなく将来あなたを悩ませ、その言語を嫌うことになります。しかし、心配しないでください。この章の後半で、文字列を記述する他の方法を確認します。
クーレイドを飲みすぎないでください
これは、Erlangが文字列操作が苦手と言われる理由です。他の多くの言語のように、組み込みの文字列型はありません。これは、Erlangが通信会社によって作成され、使用された言語であることに由来します。彼らは文字列をほとんど(または全く)使用しなかったため、公式に追加する必要性を感じませんでした。しかし、Erlangの文字列操作における無意味さのほとんどは時間とともに修正されています。VMは現在、Unicode文字列をネイティブにサポートしており、全体として文字列操作は常に高速化されています。
バイナリデータ構造として文字列を格納する方法もあり、非常に軽量で高速に操作できます。全体的に見ると、標準ライブラリにはまだいくつかの関数が不足しており、Erlangで文字列処理は確かに可能ですが、PerlやPythonなど、大量の文字列処理を必要とするタスクには、やや優れた言語があります。
リストを連結するには、++演算子を使用します。++の反対は--であり、リストから要素を削除します。
5> [1,2,3] ++ [4,5]. [1,2,3,4,5] 6> [1,2,3,4,5] -- [1,2,3]. [4,5] 7> [2,4,2] -- [2,4]. [2] 8> [2,4,2] -- [2,4,2]. []
++と--はどちらも右結合です。つまり、多くの--または++演算の要素は、次の例のように右から左に実行されます。
9> [1,2,3] -- [1,2] -- [3]. [3] 10> [1,2,3] -- [1,2] -- [2]. [2,3]
続けます。リストの最初の要素はヘッドと呼ばれ、リストの残りはテールと呼ばれます。これらを取得するために、2つの組み込み関数(BIF)を使用します。
11> hd([1,2,3,4]). 1 12> tl([1,2,3,4]). [2,3,4]
注:組み込み関数(BIF)は、通常、純粋なErlangでは実装できない関数であり、そのためC、またはErlangが実装されている言語(80年代はProlog)で定義されています。Erlangで実行できるBIFもいくつかありますが、一般的な操作の速度を上げるためにCで実装されています。その1つの例はlength(List)関数であり、(推測したとおり)引数として渡されたリストの長さを返します。
ヘッドへのアクセスまたは追加は高速で効率的です。リストを処理する必要があるほとんどすべてのアプリケーションは、常に最初にヘッドを操作します。非常に頻繁に使用されるため、パターンマッチング[Head|Tail]を使用してヘッドをテールのリストから分離するより良い方法があります。リストに新しいヘッドを追加する方法は次のとおりです。
13> List = [2,3,4]. [2,3,4] 14> NewList = [1|List]. [1,2,3,4]
リストを処理する場合、通常はヘッドから始まるため、後で操作するためにテールをすばやく格納する方法が必要です。タプルの動作と、点の値({X,Y})を展開するためにパターンマッチングを使用した方法を思い出せば、リストから最初の要素(ヘッド)をスライスオフする方法が似ていることがわかります。
15> [Head|Tail] = NewList. [1,2,3,4] 16> Head. 1 17> Tail. [2,3,4] 18> [NewHead|NewTail] = Tail. [2,3,4] 19> NewHead. 2
使用した|は、cons演算子(コンストラクタ)と呼ばれます。実際、consと値のみを使用して任意のリストを作成できます。
20> [1 | []]. [1] 21> [2 | [1 | []]]. [2,1] 22> [3 | [2 | [1 | []] ] ]. [3,2,1]
つまり、任意のリストは[Term1| [Term2 | [... | [TermN]]]]...という式で構築できます。したがって、リストは、それ自体がヘッドとそれに続くヘッドを持つテールに先行するヘッドとして再帰的に定義できます。この意味で、リストはミミズのようなものだと想像できます。半分に切っても、2匹のミミズになります。

Erlangリストの構築方法は、同様のコンストラクタに慣れていない人には時々混乱を招きます。この概念に慣れるために、これらの例をすべて読んでください(ヒント:すべて同等です)。
[a, b, c, d] [a, b, c, d | []] [a, b | [c, d]] [a, b | [c | [d]]] [a | [b | [c | [d]]]] [a | [b | [c | [d | [] ]]]]
これが理解できれば、リスト内包表記を処理できるはずです。
注:[1 | 2]という形式を使用すると、「不適切なリスト」と呼ばれるものが生成されます。不適切なリストは、[Head|Tail]の方法でパターンマッチングを行う場合に機能しますが、Erlangの標準関数(length()でも)では使用できなくなります。これは、Erlangが適切なリストを期待しているためです。適切なリストは、最後のセルとして空のリストで終わります。[2]のようなアイテムを宣言する場合、リストは自動的に適切な方法で形成されます。そのため、[1|[2]]は機能します!不適切なリストは構文的には有効ですが、ユーザー定義のデータ構造以外では非常に限られた用途しかありません。
リスト内包表記
リスト内包表記は、リストを作成または変更する方法です。また、リストを操作する他の方法と比較して、プログラムを短く、理解しやすくします。集合記法の考え方に基づいています。集合論を含む数学の授業を受けたことがある場合、または数学の表記を見たことがある場合は、その仕組みをおそらく知っているでしょう。集合記法は基本的に、そのメンバーが満たす必要があるプロパティを指定することで集合を構築する方法を伝えます。リスト内包表記は最初は理解するのが難しいかもしれませんが、努力する価値があります。コードをよりクリーンで短くするので、理解するまで例を入力してみてください!
集合記法の例は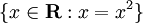 です。その集合記法は、必要な結果が、自分自身の2乗に等しいすべての実数であることを示しています。その集合の結果は{0,1}です。より簡単で省略された別の集合記法の例は
です。その集合記法は、必要な結果が、自分自身の2乗に等しいすべての実数であることを示しています。その集合の結果は{0,1}です。より簡単で省略された別の集合記法の例は{x : x > 0}です。ここでは、必要なものはx > 0であるすべての数値です。
Erlangのリスト内包表記は、他の集合から集合を構築することについてです。Lがリスト[1,2,3,4]である{2n : n in L}という集合が与えられた場合、Erlangの実装は次のようになります。
1> [2*N || N <- [1,2,3,4]]. [2,4,6,8]
数学表記とErlang表記を比較すると、変化するものはほとんどありません。括弧({})は角括弧([])になり、コロン(:)は2つのパイプ(||)になり、「in」という単語は矢印(<-)になります。記号を変更するだけで、ロジックは同じままです。上記の例では、[1,2,3,4]の各値はNに順次パターンマッチングされます。矢印は、例外をスローしない点を除いて、=演算子とまったく同じように機能します。
ブール値を返す演算子を使用して、リスト内包表記に制約を追加することもできます。1から10までのすべての偶数が必要な場合は、次のように記述できます。
2> [X || X <- [1,2,3,4,5,6,7,8,9,10], X rem 2 =:= 0]. [2,4,6,8,10]
ここで、X rem 2 =:= 0は、数値が偶数かどうかをチェックします。制約を満たすように強制するなど、リストの各要素に関数適用することを決定すると、実際的なアプリケーションが生まれます。例として、レストランを経営しているとしましょう。客が入ってきて、メニューを見て、税金(7%としましょう)を含めて3ドルから10ドルの価格のすべての品目の価格を知りたいと尋ねます。
3> RestaurantMenu = [{steak, 5.99}, {beer, 3.99}, {poutine, 3.50}, {kitten, 20.99}, {water, 0.00}].
[{steak,5.99},
{beer,3.99},
{poutine,3.5},
{kitten,20.99},
{water,0.0}]
4> [{Item, Price*1.07} || {Item, Price} <- RestaurantMenu, Price >= 3, Price =< 10].
[{steak,6.409300000000001},{beer,4.2693},{poutine,3.745}]
もちろん、小数は読みやすい方法で丸められていませんが、要点はわかります。したがって、Erlangのリスト内包表記のレシピはNewList = [Expression || Pattern <- List, Condition1, Condition2, ... ConditionN]です。Pattern <- Listの部分は、ジェネレータ式と呼ばれます。複数にすることもできます!
5> [X+Y || X <- [1,2], Y <- [2,3]]. [3,4,4,5]
これは、1+2、1+3、2+2、2+3 の演算を実行します。リスト内包表記のレシピをより汎用的にしたい場合は、NewList = [Expression || GeneratorExp1, GeneratorExp2, ..., GeneratorExpN, Condition1, Condition2, ... ConditionM] となります。ジェネレータ式とパターンマッチングを組み合わせることで、フィルタとしても機能することに注意してください。
6> Weather = [{toronto, rain}, {montreal, storms}, {london, fog},
6> {paris, sun}, {boston, fog}, {vancouver, snow}].
[{toronto,rain},
{montreal,storms},
{london,fog},
{paris,sun},
{boston,fog},
{vancouver,snow}]
7> FoggyPlaces = [X || {X, fog} <- Weather].
[london,boston]
リスト 'Weather' の要素が {X, fog} パターンに一致しない場合、リスト内包表記では単に無視されますが、= 演算子を使用した場合、例外が発生します。
現時点では、もう1つの基本的なデータ型が残っています。これは驚くべき機能で、バイナリデータの解釈を非常に簡単に行うことができます。
ビット構文!
ほとんどの言語は、数値、アトム、タプル、リスト、レコード、構造体などのデータの操作をサポートしています。しかし、それらのほとんどは、バイナリデータを操作するための非常に原始的な機能しか持っていません。Erlang は、パターンマッチングを次のレベルに引き上げることで、バイナリ値を扱う際に役立つ抽象化を提供することに重点を置いています。生のバイナリデータの処理は楽しく簡単になります(本当です)。これは、Erlang が作成された通信アプリケーションを支援するために必要でした。ビット操作には、独自の構文とイディオムがあり、最初は少し奇妙に見えるかもしれませんが、ビットとバイトが一般的にどのように機能するかを知っていれば、理解できるはずです。そうでない場合は、この章の残りの部分は飛ばしても構いません。
ビット構文は、バイナリデータを << と >> で囲み、可読性の高いセグメントに分割し、各セグメントはコンマで区切られます。セグメントは、バイナリのビットシーケンスです(必ずしもバイト境界上にある必要はありませんが、これがデフォルトの動作です)。真の色(24ビット)のオレンジ色のピクセルを保存したいとします。Photoshop や Web の CSS スタイルシートで色を確認したことがあるなら、16進数の表記法が #RRGGBB の形式であることを知っています。オレンジ色の色合いは、その表記法では #F09A29 であり、Erlang では次のように展開できます。
1> Color = 16#F09A29. 15768105 2> Pixel = <<Color:24>>. <<240,154,41>>
これは基本的に、「#F09A29 のバイナリ値を 24 ビットの空間に配置する(赤を 8 ビット、緑を 8 ビット、青も 8 ビット)ことを変数 Pixel に入れる」という意味です。この値は後でファイルに書き込むことができます。これはそれほど大したものではありませんが、ファイルに書き込んだ後、テキストエディタで開くと、読み取れない文字が大量に表示されます。ファイルから読み込むと、Erlang はバイナリを <<240,151,41>> のような見やすい形式に再び解釈します!
さらに興味深いのは、バイナリでパターンマッチングを行い、コンテンツをアンパックする機能です。
3> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
4> <<Pix1,Pix2,Pix3,Pix4>> = Pixels.
** exception error: no match of right hand side value <<213,45,132,64,76,32,76,
0,0,234,32,15>>
5> <<Pix1:24, Pix2:24, Pix3:24, Pix4:24>> = Pixels.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
コマンド3で行ったのは、バイナリで正確に4つのRGB色のピクセルを宣言することです。
式4では、バイナリコンテンツから4つの値をアンパックしようとしました。例外が発生します。セグメントが4つより多いからです。実際には12個あります!そこで、Erlang に左側の各変数が24ビットのデータを持つことを伝えます。それが Var:24 の意味です。次に、最初のピクセルを取り出して、単色の値にさらにアンパックすることができます。
6> <<R:8, G:8, B:8>> = <<Pix1:24>>. <<213,45,132>> 7> R. 213
「それは素晴らしいですね。でも、最初のカラーだけを取得したい場合はどうすればいいのでしょうか?常にこれらの値をすべてアンパックする必要があるのでしょうか?」ハッ!心配しないでください!Erlang は、さらに構文糖とパターンマッチングを導入して、あなたを助けてくれます。
8> <<R:8, Rest/binary>> = Pixels. <<213,45,132,64,76,32,76,0,0,234,32,15>> 9> R. 213
いいですね?Erlang は、バイナリセグメントを記述する複数の方法を受け入れるからです。これらはすべて有効です。
Value Value:Size Value/TypeSpecifierList Value:Size/TypeSpecifierList
ここで、Size はビットまたはバイトを表し(以下の Type と Unit に依存)、TypeSpecifierList は以下の1つ以上の属性を表します。
- 型
- 可能な値:
integer | float | binary | bytes | bitstring | bits | utf8 | utf16 | utf32 - これは使用されるバイナリデータの種類を表します。「bytes」は「binary」の略記であり、「bits」は「bitstring」の略記です。型が指定されていない場合、Erlang は「integer」型を想定します。
- 符号
- 可能な値:
signed | unsigned - 型が整数の場合のマッチングにのみ関係します。デフォルトは「unsigned」です。
- エンディアン
- 可能な値:
big | little | native - エンディアンは、型が整数、utf16、utf32、または浮動小数点数のいずれかの場合にのみ関係します。これは、システムがバイナリデータを読み取る方法に関するものです。例として、BMP 画像ヘッダー形式は、ファイルサイズを 4 バイトに格納された整数として保持します。サイズが 72 バイトのファイルの場合、リトルエンディアンシステムでは
<<72,0,0,0>>と表され、ビッグエンディアンシステムでは<<0,0,0,72>>と表されます。一方を「72」として読み取り、もう一方を「1207959552」として読み取ります。そのため、正しいエンディアンを使用してください。「native」を選択することもできます。これは、実行時に CPU がリトルエンディアンを使用するのか、ビッグエンディアンを使用するのかをネイティブに選択します。デフォルトでは、エンディアンは「big」に設定されています。 - 単位
unit:Integerと記述- これは、ビット単位の各セグメントのサイズです。許容範囲は 1~256 であり、整数、浮動小数点数、ビット文字列の場合はデフォルトで 1 に、バイナリの場合は 8 に設定されます。utf8、utf16、utf32 型では、単位を定義する必要はありません。Size と Unit の積は、セグメントが使用するビット数に等しく、8 で割り切れる必要があります。単位サイズは通常、バイトアライメントを確保するために使用されます。
TypeSpecifierList は、属性を「-」で区切って構築されます。
いくつかの例が定義を理解するのに役立つでしょう。
10> <<X1/unsigned>> = <<-44>>. <<"Ô">> 11> X1. 212 12> <<X2/signed>> = <<-44>>. <<"Ô">> 13> X2. -44 14> <<X2/integer-signed-little>> = <<-44>>. <<"Ô">> 15> X2. -44 16> <<N:8/unit:1>> = <<72>>. <<"H">> 17> N. 72 18> <<N/integer>> = <<72>>. <<"H">> 19> <<Y:4/little-unit:8>> = <<72,0,0,0>>. <<72,0,0,0>> 20> Y. 72
バイナリデータの読み取り、保存、解釈には複数の方法があることがわかります。これは少し混乱するかもしれませんが、ほとんどの言語で提供される通常のツールを使用するよりもはるかに簡単です。
標準的なバイナリ演算(ビットの左シフトと右シフト、バイナリ「and」、「or」、「xor」、「not」)も Erlang に存在します。bsl(ビット左シフト)、bsr(ビット右シフト)、band、bor、bxor、bnot 関数を使用してください。
2#00100 = 2#00010 bsl 1. 2#00001 = 2#00010 bsr 1. 2#10101 = 2#10001 bor 2#00101.
この表記法とビット構文全般を使用することで、バイナリデータの解析とパターンマッチングは非常に簡単になります。次のようなコードで TCP セグメントを解析できます。
<<SourcePort:16, DestinationPort:16, AckNumber:32, DataOffset:4, _Reserved:4, Flags:8, WindowSize:16, CheckSum: 16, UrgentPointer:16, Payload/binary>> = SomeBinary.
同じロジックを、ビデオエンコーディング、画像、その他のプロトコル実装など、バイナリデータに適用できます。
クーレイドを飲みすぎないでください
Erlang は C や C++ などの言語と比較して遅いです。忍耐強い人でない限り、上記のバイナリ構文が非常に興味深いとしても、ビデオや画像を変換するような作業を行うのはお勧めできません。Erlang は、大量の数値計算にはあまり適していません。
ただし、数値計算を必要としないアプリケーション(イベントへの反応、アトムが非常に軽量であるためメッセージパッシングなど)では、Erlang は依然として非常に高速です。ミリ秒単位でイベントを処理できるため、ソフトリアルタイムアプリケーションに最適です。
バイナリ表記には、ビット文字列というもう一つの側面があります。ビット文字列は、リストの場合と同様に言語に追加されますが、スペースの点ではるかに効率的です。これは、通常のリストが連結リスト(文字ごとに1つの「ノード」)であるのに対し、ビット文字列は C 配列のようなものであるためです。ビット文字列は <<"this is a bit string!">> の構文を使用します。リストと比較したビット文字列の欠点は、パターンマッチングと操作の簡潔さが失われることです。したがって、あまり操作されないテキストを保存する場合や、スペース効率が本当に問題になる場合に、ビット文字列が使用される傾向があります。
注:ビット文字列は非常に軽量ですが、値にタグを付けるために使用することは避けてください。{<<"temperature">>,50} のように文字列リテラルを使用したいと思うかもしれませんが、常にアトムを使用してください。この章の前半では、アトムは長さに関係なく、スペースを 4 バイトまたは 8 バイトしか占有しないと述べました。アトムを使用することで、関数の間でデータのコピーを行う場合や、別のサーバー上の別の Erlang ノードにデータを送信する場合に、基本的にオーバーヘッドが発生しません。
逆に、アトムが軽量であるからといって、文字列を置き換えるためにアトムを使用しないでください。文字列は(分割、正規表現など)操作できますが、アトムは比較することしかできません。
バイナリ内包表記
バイナリ内包表記は、ビット構文に対するリスト内包表記がリストに対するものと同じです。コードを短く簡潔にする方法です。Erlang の世界では比較的新しいものです。以前のバージョンの Erlang には存在していましたが、特別なコンパイルフラグを使用してそれらを処理するモジュールを必要としていました。R13B リビジョン(ここで使用されているもの)以降は標準となり、シェルを含むどこでも使用できます。
1> [ X || <<X>> <= <<1,2,3,4,5>>, X rem 2 == 0]. [2,4]
通常のリスト内包表記からの構文の変更点は、<- が <= になり、リスト([])の代わりにバイナリ(<<>>)を使用することだけです。この章の前半では、多くのピクセルのバイナリ値があり、パターンマッチングを使用して各ピクセルの RGB 値を取得した例を示しました。それは問題ありませんでしたが、より大きな構造では、読み取りと保守が難しくなる可能性があります。同じ演習を、はるかにクリーンな 1 行のバイナリ内包表記で行うことができます。
2> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
3> RGB = [ {R,G,B} || <<R:8,G:8,B:8>> <= Pixels ].
[{213,45,132},{64,76,32},{76,0,0},{234,32,15}]
<- を <= に変更することで、バイナリストリームをジェネレータとして使用できるようになりました。完全なバイナリ内包表記は、基本的にバイナリデータをタプル内の整数に変更しました。まったく逆のことを行うことができる別のバイナリ内包表記構文が存在します。
4> << <<R:8, G:8, B:8>> || {R,G,B} <- RGB >>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
ジェネレータがバイナリを返す場合、結果のバイナリの要素には明確に定義されたサイズが必要であることに注意してください。
5> << <<Bin>> || Bin <- [<<3,7,5,4,7>>] >>. ** exception error: bad argument 6> << <<Bin/binary>> || Bin <- [<<3,7,5,4,7>>] >>. <<3,7,5,4,7>>
上記の固定サイズルールが尊重されている場合、バイナリジェネレータを持つバイナリ内包表記も可能です。
7> << <<(X+1)/integer>> || <<X>> <= <<3,7,5,4,7>> >>. <<4,8,6,5,8>>
注:本書執筆時点では、バイナリ内包表記はほとんど使用されておらず、十分に文書化されていませんでした。そのため、それらを特定し、基本的な動作を理解するために必要な以上の詳細を掘り下げないことにしました。ビット構文全体をさらに理解するには、仕様を定義するホワイトペーパー をお読みください。