OTPを使ったアプリケーションの構築
これまでに、汎用サーバー、有限状態マシン、イベントハンドラ、スーパーバイザの使い方を見てきました。しかし、それらを組み合わせてアプリケーションやツールを構築する方法は、まだ具体的には見ていません。
Erlangアプリケーションとは、関連するコードとプロセスのグループです。*OTPアプリケーション*は、特にOTPビヘイビアをプロセスに使用し、VMがすべてをセットアップしてティアダウンする方法を指示する非常に特殊な構造でそれらをラップします。
そこでこの章では、OTPコンポーネントを使用してアプリケーションを構築しますが、完全なOTPアプリケーションは構築しません。完全なOTPアプリケーションの詳細は少し複雑で、独自の章(次の章)が必要です。この章では、プロセスプールの実装について説明します。このようなプロセスプールの背後にある考え方は、システムで実行されているリソースを汎用的な方法で管理および制限することです。
プロセスのプール

プールを使用すると、一度に実行されるプロセスの数を制限できます。プールは、実行中のワーカーの制限に達したときにジョブをキューに入れることもできます。ジョブは、リソースが解放され次第実行されるか、ユーザーに他に何もできないことを伝えることで単にブロックされます。現実世界のプールは実際にはプロセスプールとは似ていませんが、後者を使用したい理由はいくつかあります。それらには以下が含まれます
- サーバーを最大N個の同時接続に制限する。
- アプリケーションで開くことができるファイルの数を制限する。
- リリースのさまざまなサブシステムに、いくつかにはより多くのリソースを、いくつかにはより少ないリソースを許可することにより、異なる優先順位を与える。たとえば、管理用のレポートを生成するプロセスよりも、クライアント要求のプロセスを多く許可する。
- バーストで発生する一時的な高負荷下にあるアプリケーションが、タスクをキューに入れることで、その存続期間全体にわたってより安定した状態を保つことができるようにする。
したがって、プロセスプールアプリケーションは、いくつかの機能をサポートする必要があります
- アプリケーションの起動と停止
- 特定のプロセスプールの起動と停止(すべてのプールはプロセスプールアプリケーション内にあります)
- プールでタスクを実行し、プールがいっぱいの場合はタスクを開始できないことを伝える
- 空きがあればプールでタスクを実行し、そうでなければタスクがキューに入っている間、呼び出し元のプロセスを待機させ続ける。タスクを実行できるようになったら、呼び出し元を解放する。
- できるだけ早く、プールでタスクを非同期に実行する。利用可能な場所がない場合は、キューに入れて、いつでも実行する。
これらのニーズは、プログラムの設計を促進するのに役立ちます。また、スーパーバイザを使用できるようになったことも覚えておいてください。そしてもちろん、私たちはそれらを使いたいと思っています。問題は、堅牢性の点で新しい力を与えてくれる一方で、柔軟性に一定の制限を課すことです。それを探ってみましょう。
オニオンレイヤー理論

スーパーバイザを使用してアプリケーションを設計するには、何が監督を必要とし、どのように監督する必要があるかを理解しておくと役立ちます。さまざまな設定を持つさまざまな戦略があることを思い出してください。これらは、さまざまな種類のエラーを持つさまざまな種類のコードに適合します。虹色の間違いをする可能性があります!
初心者や経験豊富なErlangプログラマーでさえ、通常、状態の喪失に対処する方法に苦労しています。スーパーバイザはプロセスを強制終了し、状態は失われ、私は不幸です。これを支援するために、さまざまな種類の状態を特定します
- 静的状態。このタイプは、設定ファイル、別のプロセス、またはアプリケーションを再起動するスーパーバイザから簡単に取得できます。
- 再計算できるデータで構成される動的状態。これには、現在の状態にするために初期状態から変換する必要があった状態が含まれます
- 再計算できない動的データ。これには、ユーザー入力、ライブデータ、外部イベントのシーケンスなどが含まれる場合があります。
静的データの処理はやや簡単です。ほとんどの場合、スーパーバイザから直接取得できます。動的で再計算可能なデータについても同様です。この場合、`init/1`関数内、または実際にはコード内の任意の場所で取得して計算することができます。
最も問題のある種類の状態は、再計算できず、基本的に失われないことを願うしかない動的データです。場合によっては、そのデータをデータベースにプッシュしますが、それは必ずしも良い選択肢とは限りません。
オニオンレイヤーシステムの考え方は、さまざまな種類のコードを互いに分離することにより、これらすべての異なる状態を正しく保護できるようにすることです。これはプロセスの分離です。
静的状態は、スーパーバイザ、起動されているシステムなどによって処理できます。子が死ぬたびに、スーパーバイザはそれらを再起動し、常に利用可能な何らかの形式の静的状態を注入できます。ほとんどのスーパーバイザ定義は本質的に静的であるため、追加する監督の各レイヤーは、アプリケーションを障害とその状態の喪失から保護するシールドとして機能します。
再計算できる動的状態には、非常に多くの利用可能なソリューションがあります。スーパーバイザから送信された静的データから構築したり、他のプロセス、データベース、テキストファイル、現在の環境などから取得したりできます。再起動ごとに比較的簡単に復元できるはずです。再起動ジョブを実行するスーパーバイザがあるという事実だけで、その状態を維持するのに十分です。
動的で再計算できない種類の状態には、より思慮深いアプローチが必要です。オニオンレイヤーアプローチの真の本質はここにあります。重要なデータ(または見つけるのが最も難しいデータ)は、最も保護されたタイプである必要があるという考え方です。実際に失敗することが許されない場所を、アプリケーションの*エラーカーネル*と呼びます。

エラーカーネルは、他のどこよりも`try ... catch`を使用したい場所であり、例外的なケースの処理が不可欠です。これは、エラーがないようにしたいものです。特に元に戻す方法がない場合は、注意深いテストを行う必要があります。顧客の注文を処理中に失いたくないですよね?一部の操作は、他の操作よりも安全であると見なされます。このため、重要なデータをできるだけ安全なコアに保持し、危険なものはすべてその外に保持したいと考えています。具体的には、これは、関連するすべての種類の操作が同じ監視ツリーの一部であり、関連のない操作は異なるツリーに保持する必要があることを意味します。同じツリー内では、障害が発生しやすいが重要ではない操作は、別のサブツリーに配置できます。可能な場合は、必要なツリーの部分のみを再起動します。実際のプロセスプールの監視ツリーを設計する際に、この例を見ていきます。
プールのツリー
では、これらのプロセスプールをどのように編成すればよいでしょうか?ここには2つの考え方があります。1つはボトムアップで設計する(個々のコンポーネントをすべて記述し、必要に応じてそれらを組み合わせる)ように指示し、もう1つはトップダウンで記述する(すべてのパーツが存在するかのように設計し、次にそれらを構築する)ように指示します。どちらのアプローチも、状況と個人のスタイルに応じて同等に有効です。物事を理解しやすくするために、ここではトップダウンで物事を行います。
では、ツリーはどのように見えるべきでしょうか?私たちの要件には、プールアプリケーション全体を起動できること、多くのプールがあること、各プールにキューに入れることができる多くのワーカーがあることが含まれます。これはすでにいくつかの可能な設計上の制約を示唆しています。
プールごとに1つの`gen_server`が必要になります。サーバーのジョブは、プールにいくつのワーカーがいるかのカウンターを維持することです。便宜上、同じサーバーにタスクのキューも保持する必要があります。しかし、各ワーカーを監督する責任は誰にあるのでしょうか?サーバー自体?
サーバーでそれを行うのは興味深いことです。結局のところ、プロセスを追跡してカウントする必要があり、それ自体を監督することは、それを行うための気の利いた方法です。さらに、サーバーもプロセスも、他のすべての状態を失うことなくクラッシュすることはできません(そうでない場合、サーバーは再起動後にタスクを追跡できません)。いくつかの欠点もあります。サーバーには多くの責任があり、より脆弱と見なされる可能性があり、既存の、より適切にテストされたモジュールの機能が重複します。
すべてのワーカーが適切に説明されていることを確認する良い方法は、ワーカー専用のスーパーバイザを使用することです
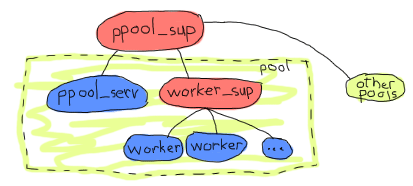
たとえば、上記のものは、すべてのプールに単一のスーパーバイザを持ちます。各プールは、実際にはプールサーバーとワーカーのスーパーバイザのセットです。プールサーバーは、ワーカーのスーパーバイザの存在を知っており、アイテムを追加するように要求します。子の追加は、これまで未知の制限がある非常に動的なものであるため、`simple_one_for_one`スーパーバイザを使用する必要があります。
**注:** `ppool`という名前が選択されているのは、Erlang標準ライブラリにすでに`pool`モジュールがあるためです。さらに、それはひどいプール関連のしゃれです。
この方法で物事を行うことの利点は、`worker_sup`スーパーバイザが単一タイプのOTPワーカーのみを追跡する必要があるため、各プールは明確に定義された種類のワーカーであり、管理と再起動の戦略が単純で定義しやすいことが保証されることです。これは、エラーカーネルがより適切に定義されている1つの例です。Web接続用のソケットのプールとログファイルを担当するサーバーの別のプールを使用している場合、アプリケーションのログファイルセクションの不正なコードまたは乱雑な権限がソケットを担当するプロセスを溺れさせないことを確認しています。ログファイルのプールがクラッシュしすぎると、シャットダウンされ、スーパーバイザが停止します。ちょっと待って!
そうです。すべてのプールが同じスーパーバイザの下にあるため、特定のプールまたはサーバーが短期間に何度も再起動すると、他のすべてのプールがダウンする可能性があります。これは、私たちが行いたいことは、監督のレベルを1つ追加することであることを意味します。これにより、一度に複数のプールを処理することもはるかに簡単になります。そのため、次のものがアプリケーションアーキテクチャになるとしましょう。
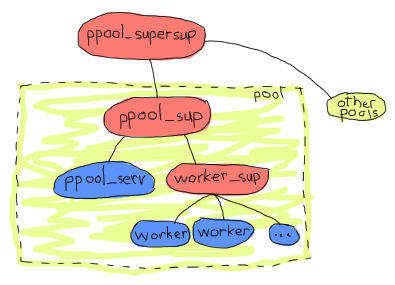
そして、それはもう少し理にかなっています。オニオンレイヤーの観点から、すべてのプールは独立しており、ワーカーは互いに独立しており、`ppool_serv`サーバーはすべてのワーカーから分離されます。それはアーキテクチャには十分であり、必要なものはすべて揃っているようです。実装に取り組むことができます。ここでも、トップからボトムへと進めます。
スーパーバイザの実装
トップレベルのスーパーバイザである`ppool_supersup`から始めることができます。必要なときにプールのスーパーバイザを起動するだけです。いくつかの関数を提供します。アプリケーション全体を起動する`start_link/0`、アプリケーションを停止する`stop/0`、特定のプールを作成する`start_pool/3`、およびその逆を行う`stop_pool/1`です。また、スーパーバイザの動作に必要な唯一のコールバックである`init/1`を忘れてはなりません
-module(ppool_supersup).
-behaviour(supervisor).
-export([start_link/0, stop/0, start_pool/3, stop_pool/1]).
-export([init/1]).
start_link() ->
supervisor:start_link({local, ppool}, ?MODULE, []).
ここでは、トップレベルのプロセスプールスーパーバイザに`ppool`という名前を付けました(これは、ノードに`gen_` *プロセスを登録することについてのOTP規則である`{local, Name}`の使用を説明しています。分散登録には別の規則が存在します)。これは、Erlangノードごとに1つの`ppool`しかないとわかっているため、競合を心配することなく名前を付けることができるためです。幸いなことに、同じ名前を使用してプール全体のセットを停止できます
%% technically, a supervisor can not be killed in an easy way.
%% Let's do it brutally!
stop() ->
case whereis(ppool) of
P when is_pid(P) ->
exit(P, kill);
_ -> ok
end.
コードのコメントで説明されているように、スーパーバイザを正常に終了することはできません。これは、OTPフレームワークがすべてのスーパーバイザに対して明確に定義されたシャットダウンプロシージャを提供していますが、現時点では使用できないためです。次の章でその方法を説明しますが、今のところ、スーパーバイザを brutallyに強制終了するのが最善の方法です。
トップレベルのスーパーバイザとは正確には何でしょうか?その唯一のタスクは、プールをメモリに保持し、それらを監督することです。この場合、それは子を持たないスーパーバイザになります
init([]) ->
MaxRestart = 6,
MaxTime = 3600,
{ok, {{one_for_one, MaxRestart, MaxTime}, []}}.
これで、個々のプールのスーパーバイザーを起動し、それらをppoolにアタッチすることに集中できます。初期要件を考慮すると、2つのパラメーターが必要になります。プールが受け入れるワーカーの数と、ワーカースーパーバイザーが各ワーカーを起動するために必要な{M,F,A}タプルです。さらに、分かりやすくするために名前も追加します。そして、この子仕様をプロセスプールのスーパーバイザーに渡して起動します。
start_pool(Name, Limit, MFA) ->
ChildSpec = {Name,
{ppool_sup, start_link, [Name, Limit, MFA]},
permanent, 10500, supervisor, [ppool_sup]},
supervisor:start_child(ppool, ChildSpec).
各プールのスーパーバイザーは永続的であるように要求され、必要な引数を持っています(プログラマーが送信したデータを静的データに変更する方法に注目してください)。プールの名前は、スーパーバイザーに渡され、子仕様の識別子としても使用されます。また、最大シャットダウン時間は10500です。この値を選択する簡単な方法はありません。すべての子が停止するのに十分な大きさであることを確認してください。必要に応じて調整し、テストして適応させてください。よく分からない場合は、infinityオプションを試しても構いません。
プールを停止するには、ppoolスーパースーパーバイザー(*supersup*!)に、一致する子を強制終了するように要求する必要があります。
stop_pool(Name) ->
supervisor:terminate_child(ppool, Name),
supervisor:delete_child(ppool, Name).
これは、プールのNameを子仕様の識別子として指定したため可能です。素晴らしい!これで、各プールの直接のスーパーバイザーに集中できます!
各ppool_supは、プールサーバーとワーカースーパーバイザーを担当します。
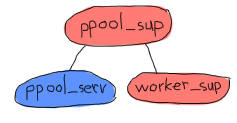
ここで面白いことに気づきましたか?ppool_servプロセスはworker_supプロセスと通信できる必要があります。同じスーパーバイザーによって同時に起動される場合、supervisor:which_children/1でトリックを行う(これはタイミングに敏感でやや危険です)、またはppool_servプロセス(ユーザーが呼び出せるようにするため)とスーパーバイザーの両方に名前を付ける以外に、ppool_servにworker_supについて知らせる方法はありません。スーパーバイザーに名前を付けたくない理由は次のとおりです。
- ユーザーはそれらを直接呼び出す必要がないため
- 動的にアトムを生成する必要があるため、不安になるため
- より良い方法があります。
基本的には、プールサーバーにワーカースーパーバイザーをppool_supに動的にアタッチさせる方法です。これが曖昧な場合は、すぐに理解できます。今はサーバーを起動するだけです。
-module(ppool_sup).
-export([start_link/3, init/1]).
-behaviour(supervisor).
start_link(Name, Limit, MFA) ->
supervisor:start_link(?MODULE, {Name, Limit, MFA}).
init({Name, Limit, MFA}) ->
MaxRestart = 1,
MaxTime = 3600,
{ok, {{one_for_all, MaxRestart, MaxTime},
[{serv,
{ppool_serv, start_link, [Name, Limit, self(), MFA]},
permanent,
5000, % Shutdown time
worker,
[ppool_serv]}]}}.
これでほぼ終わりです。Nameは、スーパーバイザー自身のpidであるself()とともにサーバーに渡されます。これにより、サーバーはワーカースーパーバイザーの生成を要求できます。MFA変数は、その呼び出しで使用され、simple_one_for_oneスーパーバイザーに実行するワーカーの種類を知らせます。
サーバーがすべてをどのように処理するかは後ほど説明しますが、今は、すべてのワーカーを担当するppool_worker_supを作成して、アプリケーションのすべてのスーパーバイザーの作成を完了します。
-module(ppool_worker_sup).
-export([start_link/1, init/1]).
-behaviour(supervisor).
start_link(MFA = {_,_,_}) ->
supervisor:start_link(?MODULE, MFA).
init({M,F,A}) ->
MaxRestart = 5,
MaxTime = 3600,
{ok, {{simple_one_for_one, MaxRestart, MaxTime},
[{ppool_worker,
{M,F,A},
temporary, 5000, worker, [M]}]}}.
簡単なことです。ワーカーは速度が要求される非常に多くの数で追加される可能性があり、さらにそのタイプを制限したいと考えているため、simple_one_for_oneを選択しました。すべてのワーカーは一時的なものであり、{M,F,A}タプルを使用してワーカーを起動するため、そこであらゆる種類のOTPビヘイビアを使用できます。

ワーカーを一時的なものにする理由は2つあります。まず、障害が発生した場合にワーカーを再起動する必要があるかどうか、またはどのような再起動戦略が必要になるかを確実に知ることはできません。次に、ユースケースによっては、ワーカーの作成者がワーカーのpidにアクセスできる場合にのみ、プールが役立つ場合があります。これを安全かつ簡単な方法で動作させるには、作成者を追跡して通知を送信せずに、好きなようにワーカーを再起動することはできません。これは、pidを取得するだけで非常に複雑になります。もちろん、pidを返さずに再起動する独自のppool_worker_supを作成することもできます。その設計には本質的に間違った点はありません。
ワーカーの操作
プールサーバーは、アプリケーションの最も複雑な部分であり、すべての巧妙なビジネスロジックが発生する場所です。サポートする必要がある操作を思い出してみましょう。
- プールでタスクを実行し、プールがいっぱいの場合はタスクを開始できないことを伝える
- 空きがあればプールでタスクを実行し、そうでない場合は、タスクがキューにある間、実行できるようになるまで呼び出しプロセスを待機させます。
- できるだけ早く、プールでタスクを非同期に実行する。利用可能な場所がない場合は、キューに入れて、いつでも実行する。
最初のものはrun/2という関数で実行され、2つ目はsync_queue/2で、最後はasync_queue/2で実行されます。
-module(ppool_serv).
-behaviour(gen_server).
-export([start/4, start_link/4, run/2, sync_queue/2, async_queue/2, stop/1]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
start(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
start_link(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start_link({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
run(Name, Args) ->
gen_server:call(Name, {run, Args}).
sync_queue(Name, Args) ->
gen_server:call(Name, {sync, Args}, infinity).
async_queue(Name, Args) ->
gen_server:cast(Name, {async, Args}).
stop(Name) ->
gen_server:call(Name, stop).
start/4とstart_link/4の場合、Argsは、スーパーバイザーに送信された{M,F,A}トリプルのA部分に渡される追加の引数になります。同期キューの場合、待機時間をinfinityに設定していることに注意してください。
前述のように、サーバー内からスーパーバイザーを起動する必要があります。コードを随時追加している場合は、空のgen_serverテンプレートを含める(または完成したファイルを使用する)ことで、サーバーを上から下まで読むのではなく、機能ごとに処理できるようになります。
最初に行うことは、スーパーバイザーの作成を処理することです。前の章の動的スーパービジョンに関する部分を覚えていれば、子を追加する必要がある場合はsimple_one_for_oneは必要ないため、supervisor:start_child/2で十分です。最初にワーカースーパーバイザーの子仕様を定義します。
%% The friendly supervisor is started dynamically!
-define(SPEC(MFA),
{worker_sup,
{ppool_worker_sup, start_link, [MFA]},
temporary,
10000,
supervisor,
[ppool_worker_sup]}).
特に変わったことはありません。次に、サーバーの内部状態を定義できます。いくつかのデータを追跡する必要があることが分かっています。実行できるプロセスの数、スーパーバイザーのpid、およびすべてのジョブのキューです。ワーカーの実行が完了した Zeitpunkt と、キューからワーカーを取得して起動する Zeitpunkt を知るには、サーバーから各ワーカーを追跡する必要があります。これを行うための適切な方法はモニターを使用することであるため、状態レコードにrefsフィールドを追加して、すべてのモニター参照をメモリに保持します。
-record(state, {limit=0,
sup,
refs,
queue=queue:new()}).
準備が整ったので、init関数の 구현 を開始できます。自然な試みは次のとおりです。
init({Limit, MFA, Sup}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
link(Pid),
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
そして、開始します。ただし、このコードは間違っています。gen_*ビヘイビアの動作方法は、ビヘイビアを生成するプロセスが、処理を再開する前にinit/1関数が戻るまで待機することです。つまり、そこでsupervisor:start_child/2を呼び出すことで、次のデッドロックが発生します。
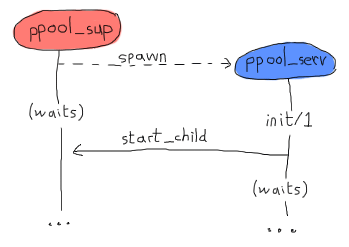
両方のプロセスは、クラッシュが発生するまで互いに待機し続けます。これを回避する最もクリーンな方法は、サーバーが自身に送信する特別なメッセージを作成して、返されるとすぐに(そしてプールスーパーバイザーが解放されるとすぐに)handle_info/2で処理できるようにすることです。
init({Limit, MFA, Sup}) ->
%% We need to find the Pid of the worker supervisor from here,
%% but alas, this would be calling the supervisor while it waits for us!
self() ! {start_worker_supervisor, Sup, MFA},
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
この方がクリーンです。次に、handle_info/2関数に移動して、次の句を追加できます。
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
link(Pid),
{noreply, S#state{sup=Pid}};
handle_info(Msg, State) ->
io:format("Unknown msg: ~p~n", [Msg]),
{noreply, State}.
最初の句がここで興味深いものです。自分自身に送信したメッセージ(必ず最初に受信されるメッセージ)を見つけ、プールスーパーバイザーにワーカースーパーバイザーを追加するように依頼し、このPidを追跡します。これで、ツリーが完全に初期化されました。ふう。すべてをコンパイルして、これまでのところ間違いがないことを確認できます。残念ながら、足りないものが多すぎるため、まだアプリケーションをテストできません。
**注:**アプリケーション全体を実行する前に構築するという考えが気に入らなくても心配しないでください。物事をこのように行うのは、全体をより明確に推論するためです。一般的な設計は念頭に置いていましたが(前に示したものと同じ)、このプールアプリケーションは、あちこちにいくつかのテストと、すべてを機能状態にするための多くのリファクタリングを使用して、少しテスト駆動型で書き始めました。
ほとんどのErlangプログラマー(他のほとんどの言語のプログラマーと同様に)は、最初の試行で本番対応のコードを作成することはできず、著者は例のように見えるほど賢くはありません。
さて、この部分は解決しました。次に、run/2関数を処理します。これは、{run, Args}形式のメッセージを使用した同期呼び出しであり、次のように動作します。
handle_call({run, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({run, _Args}, _From, S=#state{limit=N}) when N =< 0 ->
{reply, noalloc, S};
長い関数ヘッドですが、ほとんどの管理がそこで行われていることがわかります。プールに空きがある場合(元の制限Nは、最初にプールを追加するプログラマーによって決定されます)、ワーカーの起動を受け入れます。次に、モニターを設定していつ完了したかを知り、これらすべてを状態に保存し、カウンターをデクリメントして、開始します。
空きがない場合は、単にnoallocで応答します。
sync_queue/2への呼び出しは、非常に似た実装を提供します。
handle_call({sync, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({sync, Args}, From, S = #state{queue=Q}) ->
{noreply, S#state{queue=queue:in({From, Args}, Q)}};
より多くのワーカーのためのスペースがある場合、最初の句はrun/2で行ったこととまったく同じことを行います。違いは、ワーカーを実行できない場合です。前回のようにnoallocで応答する代わりに、これは呼び出し元に応答せず、From情報を保持し、ワーカーを実行するためのスペースがある後までキューに入れます。それらをデキューして処理する方法はすぐにわかりますが、今のところは、次の句を使用してhandle_call/3コールバックを終了します。
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
これは、未知のケースとstop/1呼び出しを処理します。これで、async_queue/2を機能させることに集中できます。async_queue/2は、基本的にワーカーがいつ実行されるかを気にせず、応答をまったく期待しないため、呼び出しではなくキャストにすることにしました。そのロジックは、前の2つのオプションと非常に似ていることがわかります。
handle_cast({async, Args}, S=#state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{noreply, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_cast({async, Args}, S=#state{limit=N, queue=Q}) when N =< 0 ->
{noreply, S#state{queue=queue:in(Args,Q)}};
%% Not going to explain this one!
handle_cast(_Msg, State) ->
{noreply, State}.
繰り返しますが、応答しないこと以外に大きな違いは、ワーカーの場所がない場合にキューに入れられることです。しかし、今回はFrom情報がなく、それなしでキューに送信するだけです。この場合、制限は変更されません。
何かをデキューする Zeitpunkt はいつわかりますか?まあ、モニターがあちこちに設定されていて、それらの参照をgb_setsに保存しています。ワーカーがダウンすると、通知を受けます。そこから作業しましょう。
handle_info({'DOWN', Ref, process, _Pid, _}, S = #state{refs=Refs}) ->
io:format("received down msg~n"),
case gb_sets:is_element(Ref, Refs) of
true ->
handle_down_worker(Ref, S);
false -> %% Not our responsibility
{noreply, S}
end;
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
...
handle_info(Msg, State) ->
...
このスニペットで行っているのは、受信した `'DOWN'` メッセージがワーカーからのものであることを確認することです。ワーカーから来ていない場合(これは驚くべきことですが)、単に無視します。しかし、メッセージが本当に必要なものである場合、`handle_down_worker/2` という関数を呼び出します。
handle_down_worker(Ref, S = #state{limit=L, sup=Sup, refs=Refs}) ->
case queue:out(S#state.queue) of
{{value, {From, Args}}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
gen_server:reply(From, {ok, Pid}),
{noreply, S#state{refs=NewRefs, queue=Q}};
{{value, Args}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
{noreply, S#state{refs=NewRefs, queue=Q}};
{empty, _} ->
{noreply, S#state{limit=L+1, refs=gb_sets:delete(Ref,Refs)}}
end.
これはかなり複雑です。ワーカーが停止しているので、キュー内で次に実行するワーカーを探します。これは、キューから1つの要素を取り出し、結果を確認することで行います。キューに少なくとも1つの要素がある場合、`{{value, Item}, NewQueue}` の形式になります。キューが空の場合、`{empty, SameQueue}` が返されます。さらに、値が `{From, Args}` の場合、`sync_queue/2` から来たものであり、それ以外の場合は `async_queue/2` から来たものであることがわかります。
キューにタスクがある場合のどちらのケースも、ほぼ同じように動作します。新しいワーカーがワーカースーパーバイザーに接続され、古いワーカーのモニターの参照が削除され、新しいワーカーのモニターの参照に置き換えられます。唯一の違いは、同期呼び出しの場合、手動で返信を送信するのに対し、非同期呼び出しの場合は何もせずにいられることです。大体それだけです。
キューが空だった場合は、ワーカーの制限を1つ増やすだけで他に何もする必要はありません。
最後に、標準のOTPコールバックを追加します。
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
これで、プールを使用する準備ができました!ただし、これはあまり使い勝手の良いプールではありません。使用する必要がある関数はすべてあちこちに散らばっています。いくつかは `ppool_supersup` に、いくつかは `ppool_serv` にあります。さらに、モジュール名は理由もなく長いです。使いやすくするために、アプリケーションのディレクトリに次の APIモジュール(呼び出しを抽象化しただけ)を追加します。
%%% API module for the pool
-module(ppool).
-export([start_link/0, stop/0, start_pool/3,
run/2, sync_queue/2, async_queue/2, stop_pool/1]).
start_link() ->
ppool_supersup:start_link().
stop() ->
ppool_supersup:stop().
start_pool(Name, Limit, {M,F,A}) ->
ppool_supersup:start_pool(Name, Limit, {M,F,A}).
stop_pool(Name) ->
ppool_supersup:stop_pool(Name).
run(Name, Args) ->
ppool_serv:run(Name, Args).
async_queue(Name, Args) ->
ppool_serv:async_queue(Name, Args).
sync_queue(Name, Args) ->
ppool_serv:sync_queue(Name, Args).
これで本当に完了です!
**注意:** プロセスプールは、キューに格納できるアイテムの数を制限しないことに気づいたでしょう。場合によっては、実際のサーバーアプリケーションでは、メモリ使用量が多すぎる場合のクラッシュを回避するために、キューに入れられるアイテムの数に上限を設ける必要があります。ただし、固定数の呼び出し元で `run/2` と `sync_queue/2` のみを使用する場合は、この問題を回避できます(すべてのコンテンツプロデューサーがプール内の空き領域を待つためにスタックしている場合、そもそもコンテンツの生成量が少なくなります)。
キューサイズに制限を追加することは、読者の演習として残されていますが、比較的簡単なので心配しないでください。新しいパラメータをサーバーまでのすべての関数に渡す必要があります。サーバーはキューイングの前に制限を確認します。
さらに、システムの負荷を制御するために、同期呼び出しを使用してソースに近い場所で制限を課す場合があります。同期呼び出しを使用すると、コンシューマーよりも速くプロデューサーがシステムを飽和させている場合、着信クエリをブロックできます。これは一般的に、自由奔放な負荷よりも応答性を維持するのに役立ちます。
ワーカーの作成
見てください、私はいつも嘘をついています!プールはまだ実際に使用できる状態ではありません。ワーカーがいません。忘れていました。これは残念です。なぜなら、並行アプリケーションの作成に関する章で、素晴らしいタスクリマインダーを作成したことを皆知っているからです。どうやら私には十分ではなかったので、ここでは*ナガー*を作成します。
基本的には、各タスクのワーカーとなり、ワーカーは指定された期限まで繰り返しメッセージを送信することで、私たちにしつこく催促し続けます。それは以下を行うことができます。
- 催促する時間遅延
- メッセージの送信先アドレス(pid)
- プロセス メールボックスに送信される催促メッセージ。ナガー自身の pid を含め、呼び出すことができます...
- ...タスクが完了し、ナガーが催促を停止できることを示す停止関数
さあ、始めましょう
%% demo module, a nagger for tasks,
%% because the previous one wasn't good enough
-module(ppool_nagger).
-behaviour(gen_server).
-export([start_link/4, stop/1]).
-export([init/1, handle_call/3, handle_cast/2,
handle_info/2, code_change/3, terminate/2]).
start_link(Task, Delay, Max, SendTo) ->
gen_server:start_link(?MODULE, {Task, Delay, Max, SendTo} , []).
stop(Pid) ->
gen_server:call(Pid, stop).
はい、また別の `gen_server` を使用します。人々が常にそれらを使用していることがわかるでしょう。たとえそれが適切でない場合でも!プールは `gen_server` だけでなく、OTP 準拠のプロセスであれば何でも受け入れることができることを覚えておくことが重要です。
init({Task, Delay, Max, SendTo}) ->
{ok, {Task, Delay, Max, SendTo}, Delay}.
これは基本的なデータを取得して転送するだけです。繰り返しますが、Task はメッセージとして送信されるもので、Delay は各送信の間隔の時間、Max は送信される回数、SendTo は pid またはメッセージの送信先となる名前です。Delay はタプルの3番目の要素として渡されるため、Delay ミリ秒後に `timeout` が `handle_info/2` に送信されることに注意してください。
上記のAPIを考えると、サーバーのほとんどは非常に単純です。
%%% OTP Callbacks
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(timeout, {Task, Delay, Max, SendTo}) ->
SendTo ! {self(), Task},
if Max =:= infinity ->
{noreply, {Task, Delay, Max, SendTo}, Delay};
Max =< 1 ->
{stop, normal, {Task, Delay, 0, SendTo}};
Max > 1 ->
{noreply, {Task, Delay, Max-1, SendTo}, Delay}
end.
%% We cannot use handle_info below: if that ever happens,
%% we cancel the timeouts (Delay) and basically zombify
%% the entire process. It's better to crash in this case.
%% handle_info(_Msg, State) ->
%% {noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) -> ok.
ここで多少複雑な部分は、`handle_info/2` 関数にあります。`gen_server` の章で見たように、タイムアウトが発生するたびに(この場合は Delay ミリ秒後)、`timeout` メッセージがプロセスに送信されます。これに基づいて、送信された催促の数をチェックして、さらに送信する必要があるか、単に終了する必要があるかを確認します。このワーカーが完了したので、実際にこのプロセスプールを試すことができます!
プールを実行する
これで、プールのすべてのファイルをコンパイルし、プールのトップレベルスーパーバイザー自体を起動して、プールで遊ぶことができます。
$ erlc *.erl
$ erl
Erlang R14B02 (erts-5.8.3) [source] [64-bit] [smp:4:4] [rq:4] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.8.3 (abort with ^G)
1> ppool:start_link().
{ok,<0.33.0>}
この時点から、ナガーのさまざまな機能をプールとして試すことができます。
2> ppool:start_pool(nagger, 2, {ppool_nagger, start_link, []}).
{ok,<0.35.0>}
3> ppool:run(nagger, ["finish the chapter!", 10000, 10, self()]).
{ok,<0.39.0>}
4> ppool:run(nagger, ["Watch a good movie", 10000, 10, self()]).
{ok,<0.41.0>}
5> flush().
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.39.0>,"finish the chapter!"}
ok
6> ppool:run(nagger, ["clean up a bit", 10000, 10, self()]).
noalloc
7> flush().
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
...
同期型の非キュー実行では、すべてがかなりうまく機能しているようです。プールが開始され、タスクが追加され、メッセージが正しい宛先に送信されます。許可されているよりも多くのタスクを実行しようとすると、割り当てが拒否されます。クリーンアップする時間はありません、申し訳ありません!しかし、他のものはまだ正常に動作しています。
**注意:** `ppool` は `start_link/0` で開始されます。シェルでエラーが発生した場合、プール全体が停止し、最初からやり直す必要があります。この問題は次の章で対処します。
**注意:** もちろん、よりクリーンなナガーは、すべての適切なメディアにメッセージを正しく転送するために使用されるイベントマネージャーを呼び出すでしょう。しかし実際には、多くの製品、プロトコル、ライブラリは変更される傾向があり、外部の依存関係が時代遅れになると読めなくなる本がいつも嫌いでした。そのため、このチュートリアルでは、外部の依存関係を可能な限り低く抑えるか、まったく存在しないようにする傾向があります。
キューイング機能(非同期)を試すことができます。確認のためです。
8> ppool:async_queue(nagger, ["Pay the bills", 30000, 1, self()]).
ok
9> ppool:async_queue(nagger, ["Take a shower", 30000, 1, self()]).
ok
10> ppool:async_queue(nagger, ["Plant a tree", 30000, 1, self()]).
ok
<wait a bit>
received down msg
received down msg
11> flush().
Shell got {<0.70.0>,"Pay the bills"}
Shell got {<0.72.0>,"Take a shower"}
<wait some more>
received down msg
12> flush().
Shell got {<0.74.0>,"Plant a tree"}
ok
素晴らしい!キューイングが機能しています。ここでのログはすべてを明確に示しているわけではありませんが、そこで起こっているのは、最初の2つのナガーが可能な限り早く実行されることです。次に、ワーカーの制限に達し、3番目のワーカー(木の植栽)をキューに入れる必要があります。請求書の支払いの催促が完了すると、ツリーナガーがスケジュールされ、少し遅れてメッセージを送信します。
同期型は異なって動作します。
13> ppool:sync_queue(nagger, ["Pet a dog", 20000, 1, self()]).
{ok,<0.108.0>}
14> ppool:sync_queue(nagger, ["Make some noise", 20000, 1, self()]).
{ok,<0.110.0>}
15> ppool:sync_queue(nagger, ["Chase a tornado", 20000, 1, self()]).
received down msg
{ok,<0.112.0>}
received down msg
16> flush().
Shell got {<0.108.0>,"Pet a dog"}
Shell got {<0.110.0>,"Make some noise"}
ok
received down msg
17> flush().
Shell got {<0.112.0>,"Chase a tornado"}
ok
繰り返しますが、ログは自分で試した場合(お勧めします)ほど明確ではありません。基本的なイベントシーケンスは、2人のワーカーがプールに追加されることです。それらは実行されておらず、3番目のワーカーを追加しようとすると、シェルは `ppool_serv`(プロセス名 `nagger` の下)がワーカーのダウンメッセージ(`received down msg`)を受信するまでロックされます。その後、`sync_queue/2` の呼び出しが返され、真新しいワーカーの pid が提供されます。
これでプール全体を削除できます。
18> ppool:stop_pool(nagger). ok 19> ppool:stop(). ** exception exit: killed
`ppool:stop()` を呼び出すだけで、すべてのプールが終了しますが、多くのエラーメッセージが表示されます。これは、`ppool_supersup` プロセスを正しく停止するのではなく、強制終了するためです(その結果、すべての子プールがクラッシュします)。ただし、次の章では、それをクリーンに行う方法について説明します。
プールのクリーニング
すべてを振り返ると、やや簡単な方法でリソース割り当てを行うためのプロセスプールを作成することができました。すべてを並列に処理でき、制限でき、他のプロセスから呼び出すことができます。クラッシュしたアプリケーションの一部は、スーパーバイザーの助けを借りて、アプリケーション全体を壊すことなく透過的に置き換えることができます。プールアプリケーションの準備ができたら、非常に少ないコードでリマインダーアプリのかなりの部分を書き直しました。
単一コンピューターの障害分離が考慮され、並行性が処理され、シェルから実行するための適切な方法をまだ見ていないにもかかわらず、かなり堅牢なサーバーサイドソフトウェアを作成するのに十分なアーキテクチャブロックができました...
次の章では、`ppool` アプリケーションを、他の製品で出荷して使用できる、実際の OTP アプリケーションにパッケージ化する方法を説明します。これまでのところ、OTP のすべての高度な機能を見てきたわけではありませんが、OTP と Erlang(少なくとも非分散部分)に関する中級から上級初期の議論のほとんどを理解できるレベルにあると言えるでしょう。それはかなり良いことです!